I have a pandas dataframe like as shown below
ID,color
1, Yellow
1, Red
1, Green
2, Red
2, np.nan
3, Green
3, Red
3, Green
4, Yellow
4, Red
5, Green
5, np.nan
6, Red
7, Red
fd = pd.read_clipboard(sep=',')
As you can see in the input dataframe, some ID's have multiple colors associated to them.
So, whenever there is multiple color associated to them, I would like to select only one color based on the below criteria
['Green','Red','Yellow'] = Choose 'Green'
['Red', 'Yellow'] = Choose 'Yellow'
['Green', 'Yellow'] = Choose 'Green'
Basically, Green is given 1st preference. 2nd preference is for Yellow and last preference is for Red.
So, if an ID whenever has Green, choose Green (don't care about other colors).
If an ID whenever has Yellow and Red, choose Yellow
If an ID for its all rows has only NA, leave it as NA
I tried the below but this only gets me the list of color
fd.groupby('ID',as_index=False)['color'].aggregate(lambda x: list(x))
fd[final_color] = [if i[0] =='Green' for i in fd[col]]
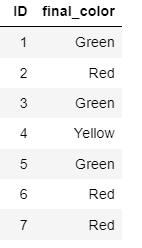
I expect my output to be like as shown below
CodePudding user response:
Sort the values of dataframe on color with the help of the preference dictionary, then drop the duplicates on ID
d = {'Green': 1, 'Yellow': 2, 'Red': 3}
df.sort_values('color', key=lambda c: c.map(d)).drop_duplicates('ID')
Alternative approach by first converting the color column to ordered categorical type, then groupby and aggregate to select the min value
df['color'] = pd.Categorical(df['color'], ['Green', 'Yellow', 'Red'], True)
df.groupby('ID', as_index=False)['color'].agg('min')
ID color
0 1 Green
1 2 Red
2 3 Green
3 4 Yellow
4 5 Green
5 6 Red
6 7 Red
CodePudding user response:
One way to solve this is to implement a custom sorting:
sort_preference = {
'Green': 0,
'Yellow': 1,
}
(
fd
.sort_values(by=['color'], key=lambda x: x.map(sort_preference))
.groupby('ID')
.head(1)
)
CodePudding user response:
Without sorting, you can use idxmin if you map your color with numeric values:
d = {'Green': 1, 'Yellow': 2, 'Red': 3}
out = df.loc[df.assign(num=df['color'].map(d)).groupby('ID')['num'].idxmin()]
print(out)
# Output
ID color
2 1 Green
3 2 Red
5 3 Green
8 4 Yellow
10 5 Green
12 6 Red
13 7 Red