As I increase the number or builds or workloads, using the code I have, I have to modify the bar_width to have everything fit.
I've been looking for a way to auto format the plot but can't seem to find any thing that works. Hoping someone on the internet knows of a better way.
import matplotlib.pyplot as plt
import numpy as np
workloads = (
"Workload 1",
"Workload 2",
"Workload 3",
"Workload 4",
"Workload 5",
"Workload 6",
)
# list of tuples
# tuple key:
# (label, data values positional to workloads, data stdev positional to workloads)
data = [
("build 1", (133_289, 163_421, 180_473, 24_978, 47_761, 47_167), (9_093, 6_740, 4_085, 7, 44, 96)),
("build 2", (163_156, 201_082, 224_287, 25_000, 47_869, 47_285), (2_306, 1_119, 780, 2, 19, 30)),
("build 3", (121_760, 148_433, 163_835, 24_975, 47_594, 47_030), (3_232, 6_995, 5_660, 3, 96, 347)),
("build 4", (136_456, 163_810, 180_590, 24_991, 47_714, 47_262), (1_623, 2_147, 2_770, 5, 22, 6)),
("build 5", (150_551, 182_301, 199_579, 24_992, 47_648, 47_169), (2_216, 3_590, 5_386, 4, 43, 151)),
("build 6", (121_390, 146_764, 161_634, 24_981, 47_599, 47_056), (4_454, 6_107, 7_102, 4, 35, 155)),
("build 7", (136_456, 163_810, 180_590, 24_991, 47_714, 47_262), (1_623, 2_147, 2_770, 5, 22, 6)),
("build 8", (150_551, 182_301, 199_579, 24_992, 47_648, 47_169), (2_216, 3_590, 5_386, 4, 43, 151)),
("build 9", (121_390, 146_764, 161_634, 24_981, 47_599, 47_056), (4_454, 6_107, 7_102, 4, 35, 155)),
("build 10", (121_390, 146_764, 161_634, 24_981, 47_599, 47_056), (4_454, 6_107, 7_102, 4, 35, 155)),
]
# the x locations for the groups, specified by the number of items in workloads
ind = np.arange(len(workloads))
# the width of the bars
bar_width = 0.10
fig, ax = plt.subplots()
bars = []
for i, data_point in enumerate(data):
my_label = data_point[0]
my_data = data_point[1]
my_data_stdev = data_point[2]
bars.append(ax.bar(ind bar_width * i, my_data, bar_width, yerr=my_data_stdev, label=my_label))
# Add some text for labels, title and custom x-axis tick labels, etc.
ax.set_ylabel("Data value")
ax.set_title("Builds")
ax.set_xticks(ind)
ax.set_xticklabels(workloads)
ax.legend()
# rotate the x-axis labels 22.5 degrees so we can better see them
# this is for dates but seems to work for x-axis labels
fig.autofmt_xdate(rotation=22.5)
plt.show()
CodePudding user response:
You could introduce a variable bar_total_width to indicate the width of the group of bars belonging to one label. Then, the width of the individual bars would be the total width divided by the number of bars in each group. By subtracting half the total width of the position, the labels can be placed at the center of each group. (Also note that ax.set_xticklabels() has a parameter for the rotation. Or you could use ax.tick_params(axis=x, rotation=...).)
The following example uses 0.9 for the total bar width, so leaving a gap of 0.1 between the groups.
import matplotlib.pyplot as plt
import numpy as np
workloads = ("Workload 1", "Workload 2", "Workload 3", "Workload 4", "Workload 5", "Workload 6",)
# tuple key: (label, data values positional to workloads, data stdev positional to workloads)
data = [("build 1", (133_289, 163_421, 180_473, 24_978, 47_761, 47_167), (9_093, 6_740, 4_085, 7, 44, 96)),
("build 2", (163_156, 201_082, 224_287, 25_000, 47_869, 47_285), (2_306, 1_119, 780, 2, 19, 30)),
("build 3", (121_760, 148_433, 163_835, 24_975, 47_594, 47_030), (3_232, 6_995, 5_660, 3, 96, 347)),
("build 4", (136_456, 163_810, 180_590, 24_991, 47_714, 47_262), (1_623, 2_147, 2_770, 5, 22, 6)),
("build 5", (150_551, 182_301, 199_579, 24_992, 47_648, 47_169), (2_216, 3_590, 5_386, 4, 43, 151)),
("build 6", (121_390, 146_764, 161_634, 24_981, 47_599, 47_056), (4_454, 6_107, 7_102, 4, 35, 155)),
("build 7", (136_456, 163_810, 180_590, 24_991, 47_714, 47_262), (1_623, 2_147, 2_770, 5, 22, 6)),
("build 8", (150_551, 182_301, 199_579, 24_992, 47_648, 47_169), (2_216, 3_590, 5_386, 4, 43, 151)),
("build 9", (121_390, 146_764, 161_634, 24_981, 47_599, 47_056), (4_454, 6_107, 7_102, 4, 35, 155)),
("build 10", (121_390, 146_764, 161_634, 24_981, 47_599, 47_056), (4_454, 6_107, 7_102, 4, 35, 155))]
# the x locations for the groups, specified by the number of items in workloads
ind = np.arange(len(workloads))
# the width of the bars
bar_total_width = 0.9
bar_width = bar_total_width / len(data)
fig, ax = plt.subplots()
for i, data_point in enumerate(data):
my_label = data_point[0]
my_data = data_point[1]
my_data_stdev = data_point[2]
bars_i = ax.bar(ind - bar_total_width/2 bar_width * i, my_data, bar_width, yerr=my_data_stdev, label=my_label)
# Add some text for labels, title and custom x-axis tick labels, etc.
ax.set_ylabel("Data value")
ax.set_title("Builds")
ax.set_xticks(ind)
ax.set_xticklabels(workloads, rotation=20)
ax.margins(x=0.01) # less white space left and right
ax.legend()
plt.tight_layout()
plt.show()
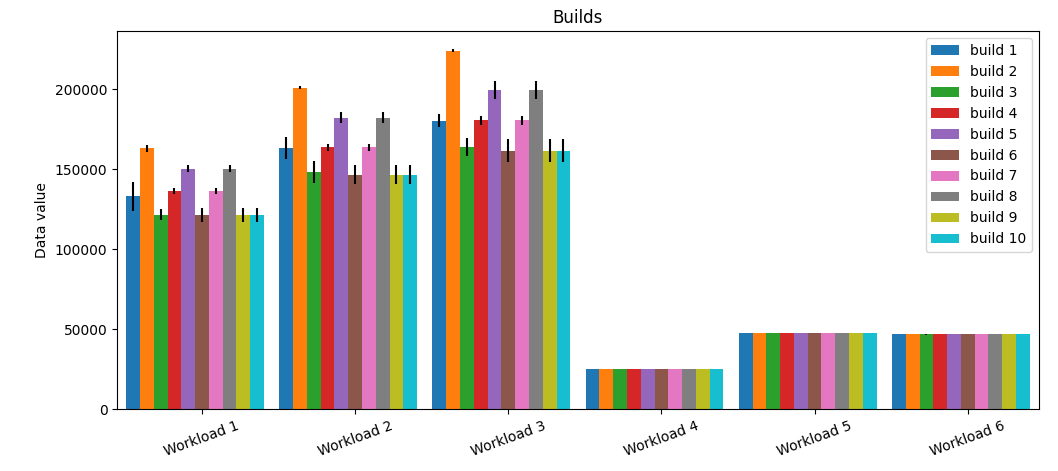
All this can be simplified a lot by creating dataframes and using pandas plotting. The total width and the rotation of the labels are parameters to the plotting function, the bar positions and the legend come automatically.
import matplotlib.pyplot as plt
import numpy as np
workloads = ("Workload 1", "Workload 2", "Workload 3", "Workload 4", "Workload 5", "Workload 6",)
# tuple key: (label, data values positional to workloads, data stdev positional to workloads)
data = [("build 1", (133_289, 163_421, 180_473, 24_978, 47_761, 47_167), (9_093, 6_740, 4_085, 7, 44, 96)),
("build 2", (163_156, 201_082, 224_287, 25_000, 47_869, 47_285), (2_306, 1_119, 780, 2, 19, 30)),
("build 3", (121_760, 148_433, 163_835, 24_975, 47_594, 47_030), (3_232, 6_995, 5_660, 3, 96, 347)),
("build 4", (136_456, 163_810, 180_590, 24_991, 47_714, 47_262), (1_623, 2_147, 2_770, 5, 22, 6)),
("build 5", (150_551, 182_301, 199_579, 24_992, 47_648, 47_169), (2_216, 3_590, 5_386, 4, 43, 151)),
("build 6", (121_390, 146_764, 161_634, 24_981, 47_599, 47_056), (4_454, 6_107, 7_102, 4, 35, 155)),
("build 7", (136_456, 163_810, 180_590, 24_991, 47_714, 47_262), (1_623, 2_147, 2_770, 5, 22, 6)),
("build 8", (150_551, 182_301, 199_579, 24_992, 47_648, 47_169), (2_216, 3_590, 5_386, 4, 43, 151)),
("build 9", (121_390, 146_764, 161_634, 24_981, 47_599, 47_056), (4_454, 6_107, 7_102, 4, 35, 155)),
("build 10", (121_390, 146_764, 161_634, 24_981, 47_599, 47_056), (4_454, 6_107, 7_102, 4, 35, 155))]
fig, ax = plt.subplots()
df_means = pd.DataFrame(index=workloads)
df_stdevs = pd.DataFrame(index=workloads)
for my_label, means, stdevs in data:
df_means[my_label] = means
df_stdevs[my_label] = stdevs
yerr = df_stdevs.values.T
df_means.plot.bar(yerr=yerr, rot=20, width=0.9, capsize=1, alpha=0.7, ax=ax)
# Add some text for labels, title and custom x-axis tick labels, etc.
ax.set_ylabel("Data value")
ax.set_title("Builds")
ax.margins(x=0.01) # less white space left and right
plt.tight_layout()
plt.show()
Even more automation would come via Seaborn. Seaborn will calculate the means and the standard deviations from the original data, and create the full bar plot with error bars and legend in one go. Seaborn needs a long form dataframe with 3 columns: one for the workload ID, one for the build ID and only one for the value.
With columns named Workload, Build and Value, the command would be (and supposing multiple rows with the same workload and build IDs):
import seaborn as sns
sns.barplot(data=df, x='Workload', y='value', hue='Build')