I'm just learning R fundamentals, and I would like to ask your help with data visualization, and specifically time series. I'm studying how vote shares of a specific category of political parties (right-wing populists) vary overtime in each country from 2009 to 2019. Here's my dataset:
dput(votesharespop)
structure(list(country = c("Austria", "Belgium", "Bulgaria",
"Czech Republic", "Denmark", "Estonia", "Finland", "France",
"Germany", "Great Britain", "Greece", "Hungary", "Italy", "Lithuania",
"Luxembourg", "Netherlands", "Poland", "Romania", "Portugal",
"Slovakia", "Slovenia", "Spain", "Sweden", "Austria", "Belgium",
"Bulgaria", "Czech Republic", "Denmark", "Estonia", "Finland",
"France", "Germany", "Great Britain", "Greece", "Hungary", "Italy",
"Lithuania", "Luxembourg", "Netherlands", "Poland", "Romania",
"Portugal", "Slovakia", "Slovenia", "Spain", "Sweden", "Austria",
"Belgium", "Bulgaria", "Czech Republic", "Denmark", "Estonia",
"Finland", "France", "Germany", "Great Britain", "Greece", "Hungary",
"Italy", "Lithuania", "Luxembourg", "Netherlands", "Poland",
"Romania", "Portugal", "Slovakia", "Slovenia", "Spain", "Sweden"
), year = c(2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009,
2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009,
2009, 2009, 2009, 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014,
2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014,
2014, 2014, 2014, 2014, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
2019, 2019, 2019, 2019, 2019), vote_share = c(17.3, 15.7, 16.7,
4.3, 15.3, 0, 9.8, 8.1, 1.7, 22.7, 7.2, 71.2, 45.5, 12.2, 7.4,
17, 27.4, 8.7, 0, 5.6, 35.2, 0, 3.3, 20.2, 7.6, 16.8, 4.8, 26.6,
5.3, 12.9, 28.7, 0.4, 28.6, 6.2, 66.2, 26.7, 14.3, 7.5, 13.3,
31.8, 2.7, 0, 3.6, 28.8, 1.6, 9.7, 17.2, 13.8, 14.6, 10, 10.8,
12.7, 13.8, 26.8, 11, 34.9, 6.2, 62.2, 49.5, 2.7, 10, 14.5, 49.1,
0, 1.5, 7.3, 30.3, 6.2, 15.3), continent = c("Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe")), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -69L))
My aim was to get something like this (no interactive):
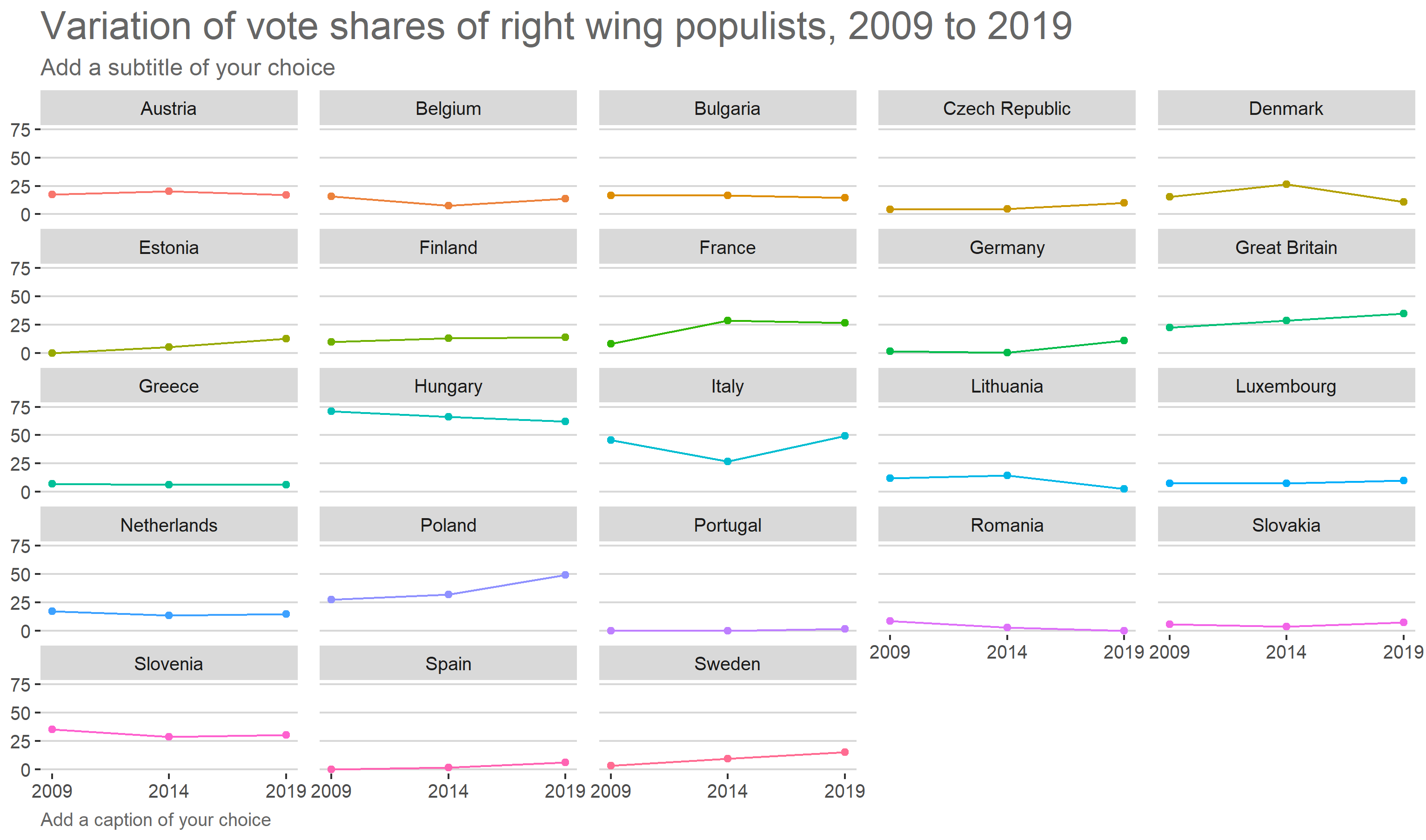
Or something like facets, but for each country.
Thank you very much for your attention.
CodePudding user response:
Data
votesharespop <- structure(list(country = c("Austria", "Belgium", "Bulgaria",
"Czech Republic", "Denmark", "Estonia", "Finland", "France",
"Germany", "Great Britain", "Greece", "Hungary", "Italy", "Lithuania",
"Luxembourg", "Netherlands", "Poland", "Romania", "Portugal",
"Slovakia", "Slovenia", "Spain", "Sweden", "Austria", "Belgium",
"Bulgaria", "Czech Republic", "Denmark", "Estonia", "Finland",
"France", "Germany", "Great Britain", "Greece", "Hungary", "Italy",
"Lithuania", "Luxembourg", "Netherlands", "Poland", "Romania",
"Portugal", "Slovakia", "Slovenia", "Spain", "Sweden", "Austria",
"Belgium", "Bulgaria", "Czech Republic", "Denmark", "Estonia",
"Finland", "France", "Germany", "Great Britain", "Greece", "Hungary",
"Italy", "Lithuania", "Luxembourg", "Netherlands", "Poland",
"Romania", "Portugal", "Slovakia", "Slovenia", "Spain", "Sweden"
), year = c(2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009,
2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009, 2009,
2009, 2009, 2009, 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014,
2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014,
2014, 2014, 2014, 2014, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
2019, 2019, 2019, 2019, 2019), vote_share = c(17.3, 15.7, 16.7,
4.3, 15.3, 0, 9.8, 8.1, 1.7, 22.7, 7.2, 71.2, 45.5, 12.2, 7.4,
17, 27.4, 8.7, 0, 5.6, 35.2, 0, 3.3, 20.2, 7.6, 16.8, 4.8, 26.6,
5.3, 12.9, 28.7, 0.4, 28.6, 6.2, 66.2, 26.7, 14.3, 7.5, 13.3,
31.8, 2.7, 0, 3.6, 28.8, 1.6, 9.7, 17.2, 13.8, 14.6, 10, 10.8,
12.7, 13.8, 26.8, 11, 34.9, 6.2, 62.2, 49.5, 2.7, 10, 14.5, 49.1,
0, 1.5, 7.3, 30.3, 6.2, 15.3), continent = c("Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe", "Europe", "Europe", "Europe",
"Europe", "Europe", "Europe", "Europe")), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -69L))
Code
library(ggplot2)
library(ggthemes) # to access theme_hc()
ggplot(data = votesharespop, mapping = aes(x = year, y = vote_share, color = country)) # specify data, x-axis, y-axis and grouping variable
geom_line() # a line per group
geom_point() # points per group
theme_hc() # a ggtheme, similar to your example
labs(title = "Variation of vote shares of right wing populists, 2009 to 2019", # plot title
subtitle = "Add a subtitle of your choice", # plot subtitle
caption = "Add a caption of your choice") # plot caption
theme(legend.position = "right", # move legend to the right hand side of the plot
axis.title.x = element_blank(), # remove x axis title
axis.title.y = element_blank(), # remove y axis title
legend.title = element_blank(), # remove legend title
plot.title = element_text(size = 20, color = "gray40"), # change size and color of plot title
plot.subtitle = element_text(color = "gray40"), # change color of subtitle
plot.caption = element_text(color = "gray40", hjust = 0)) # change color of caption and left-align
scale_y_continuous(breaks = seq(0, 80, by = 20)) # specify min, max and break distance for y axis
scale_x_continuous(breaks = seq(2009, 2019, by = 5)) # specify min, max and break distance for x axis
expand_limits(y = c(0, 80))
Output
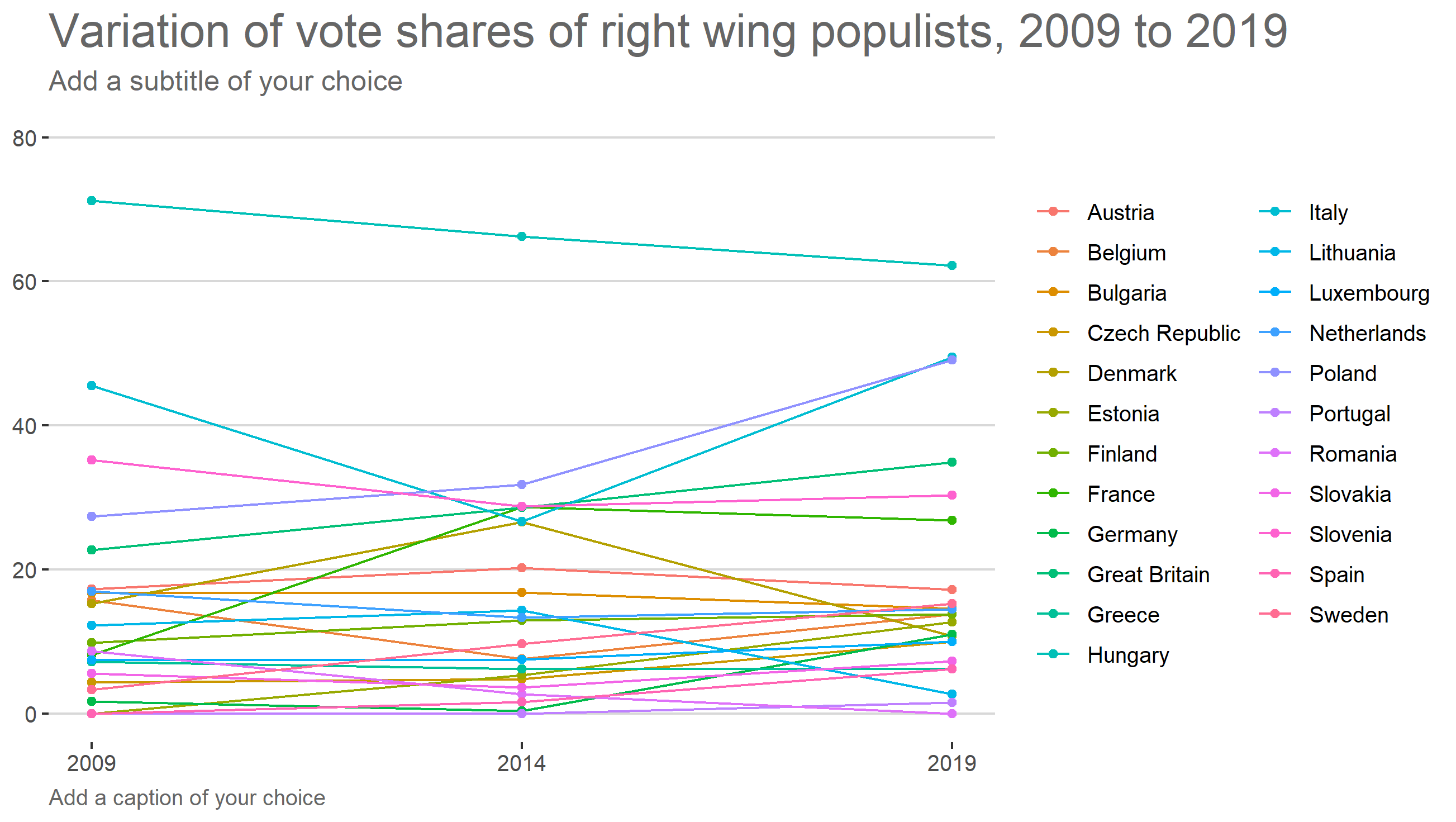
Note however, that for multiple groups, the colors can be quite indistinguishable. It might be preferable to go with facet_wrap
Code
ggplot(data = votesharespop, mapping = aes(x = year, y = vote_share, color = country)) # specify data, x-axis, y-axis and grouping variable
geom_line() # a line per group
geom_point() # points per group
theme_hc() # a ggtheme, similar to your example
labs(title = "Variation of vote shares of right wing populists, 2009 to 2019", # plot title
subtitle = "Add a subtitle of your choice", # plot subtitle
caption = "Add a caption of your choice") # plot caption
theme(legend.position = "right", # move legend to the right hand side of the plot
axis.title.x = element_blank(), # remove x axis title
axis.title.y = element_blank(), # remove y axis title
legend.title = element_blank(), # remove legend title
plot.title = element_text(size = 20, color = "gray40"), # change size and color of plot title
plot.subtitle = element_text(color = "gray40"), # change color of subtitle
plot.caption = element_text(color = "gray40", hjust = 0)) # change color of caption and left-align
scale_y_continuous(breaks = seq(0, 75, by = 25)) # specify min, max and break distance for y axis
scale_x_continuous(breaks = seq(2009, 2019, by = 5)) # specify min, max and break distance for x axis
expand_limits(y = c(0, 75)) # adjust y axis limits
facet_wrap(~ country) # facet wrap
theme(legend.position = "none") # remove legend, since not needed anymore in facet_wrap
theme(panel.spacing.x = unit(4, "mm")) # avoid overlapping of x axis text
Output