I have a dataframe which is the result of a concatenation of dataframe. I use "keys= " option for the title of each blocks when I export in Excel.
And now I want define the ID2 as an index with ID. (For have a multindex)
I tried to use .resetindex, but it didn't work like I want.
I have:
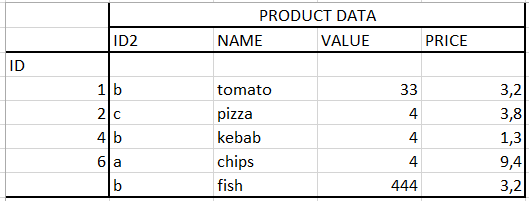
I want:
![[1]: https://i.stack.imgur.com/mjVgH.png](https://img.codepudding.com/202203/3d66c540fe104c728137dccab0037d91.png)
CodePudding user response:
You can extract your indexes to lists and to create a MultiIndex object, and then simply define the index of your DataFrame with this MultiIndex. This works on my side (pandas imported as pd):
Let's assume your initial DataFrame is this one (just a smaller version of what you have):
df = pd.DataFrame({'ID2': ['b','c','b'], 'name' : ['tomato', 'pizza', 'kebap']}, index = [1,2,4])
Then, we extract the final indices from the index and from the column of the dataframe in order to build a list of tuples, with which you create the multiindex with pandas.MuliIndex method:
ID2 = df.ID2.to_list()
ID1 = df.index.to_list()
indexes = [(id1, id2) for id1,id2 in zip(ID1,ID2)]
final_indices = pd.MultiIndex.from_tuples(indexes, names=["Id1", "Id2"])
Finally, you redefine your index and you can drop the 'ID2' column:
df.index = final_indices
df = df.drop('ID2', axis = 1)
This gives the following DataFrame:
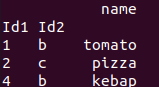
Note: I also tried with the df.reindex method, but the values of the DataFrame became NaN, I do not know why.