I have a table in Snowflake containing time based event data, with different columns, and one _timestamp column of a Timestamp type. The _timestsamp column is also the clustering key of that table.
A very basic usecase on that table would be to see the latest 100 events:
SELECT * FROM table ORDER BY _timestamp desc limit 100
However, this query is very slow on a medium WH. (60 seconds, on a few hundred milions of record).
Looking at the query profile, it looks like no partitions are pruned, meaning that snowflake is ordering the entire dataset before doing the limit. I imagined that the micro partitions are sorted, or at least contains metadata that will allow to only look at the partitions that have the latest timestamps.
In Postgres/MySQL, this query would be instant with an index on that timestamp column, since only the "end" of the index will be scanned.
Is there a way to help snowflake perform this query better? Is there something that needs to be done in ingestion time / query time?
CodePudding user response:
LIMIT in order by would not help to speed up performance from perspective of working on reduced data-set, as ORDER BY is performed on the entire data before applying LIMIT.
For partition pruning, we also need to consider the selectivity of clustering key. _timestamp would most likely have all distinct values and there is no predicate to restrict which _timestamp value to choose as ORDER BY is on entire data-set and hence there will be no pruning as entire data-set will have to scanned for sorting (or getting sorted result-set).
Good information here - 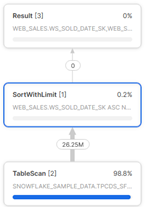
I have quoted below from snowflake documentation (https://docs.snowflake.com/en/user-guide/ui-query-profile.html#profile-overview-operator-details).
SortWithLimit Produces a part of the input sequence after sorting, typically a result of an ORDER BY ... LIMIT ... OFFSET ... construct in SQL. Attributes: • Sort keys — expression defining the sorting order. • Number of rows — number of rows produced. • Offset — position in the ordered sequence from which produced tuples are emitted.
CodePudding user response:
Without a WHERE clause, you won't prune anything and the ORDER BY will sort everything before running the LIMIT. If you want this to run faster and the data is clustered by _timestamp, then be sure to use a WHERE clause with a reasonably small date range as well as the LIMIT. For example, pick a date that is greater than yesterday (or last week or last month depending on larger your dataset is) so that Snowflake only has to fetch the most recent micropartitions and sort far less data.
Your other option is to not sort the data if the purpose of your limit is to just get a sample of the data, but that is likely a different use-case than what you are requesting.
CodePudding user response:
Is there a was you can show us the query profile of the SQL statement. Other thing could be check if the columns that you are in the WHERE clause of the SQL are part of the Clustering key, if not try adding them and see if it helps.