I have a BigQuery table with this data
client spent balance date
A 20 500 2022-01-01
A 10 490 2022-01-02
A 50 440 2022-01-03
B 200 1000 1995-07-09
B 300 700 1998-08-11
B 100 600 2002-04-17
C 2 100 2021-01-04
C 10 90 2021-06-06
C 70 20 2021-10-07
I need the latest balance of each client based on the date:
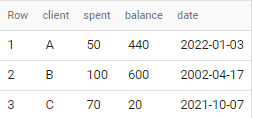
client spent balance date
A 50 440 2022-01-03
B 100 600 2002-04-17
C 70 20 2021-10-07
distinct does not work like in sql and group on client does also not work because I need count, sum, etc. with the other columns when I use group.
For just one client I use:
SELECT balance FROM `table` WHERE client = "A" ORDER BY date DESC LIMIT 1.
But how can I get this data for every client in just one statement.
I tried with subselect
SELECT client,
(SELECT balance FROM ` table ` WHERE client = tb. client ORDER by date DESC limit 1) AS bal
FROM `table` AS tb;
and got the error:
Correlated subqueries that reference other tables are not supported unless they can be de-correlated, such as by transforming them into an efficient JOIN.
I don’t know how to make a JOIN out of this subquery to make it work.
Hope you have an idea.
CodePudding user response:
Use below
select * from your_table
qualify 1 = row_number() over(partition by client order by date desc)
if applied to sample data in your question - output is
CodePudding user response:
have you tried using row_number window function?
select client, spent, balance, date
from (
select client, spent, balance, date
, ROW_NUMBER() OVER (PARTITION BY client ORDER BY date DESC) AS row_num -- adding row number, starting from latest date
from table
)
where row_num = 1 -- filter out only the latest date