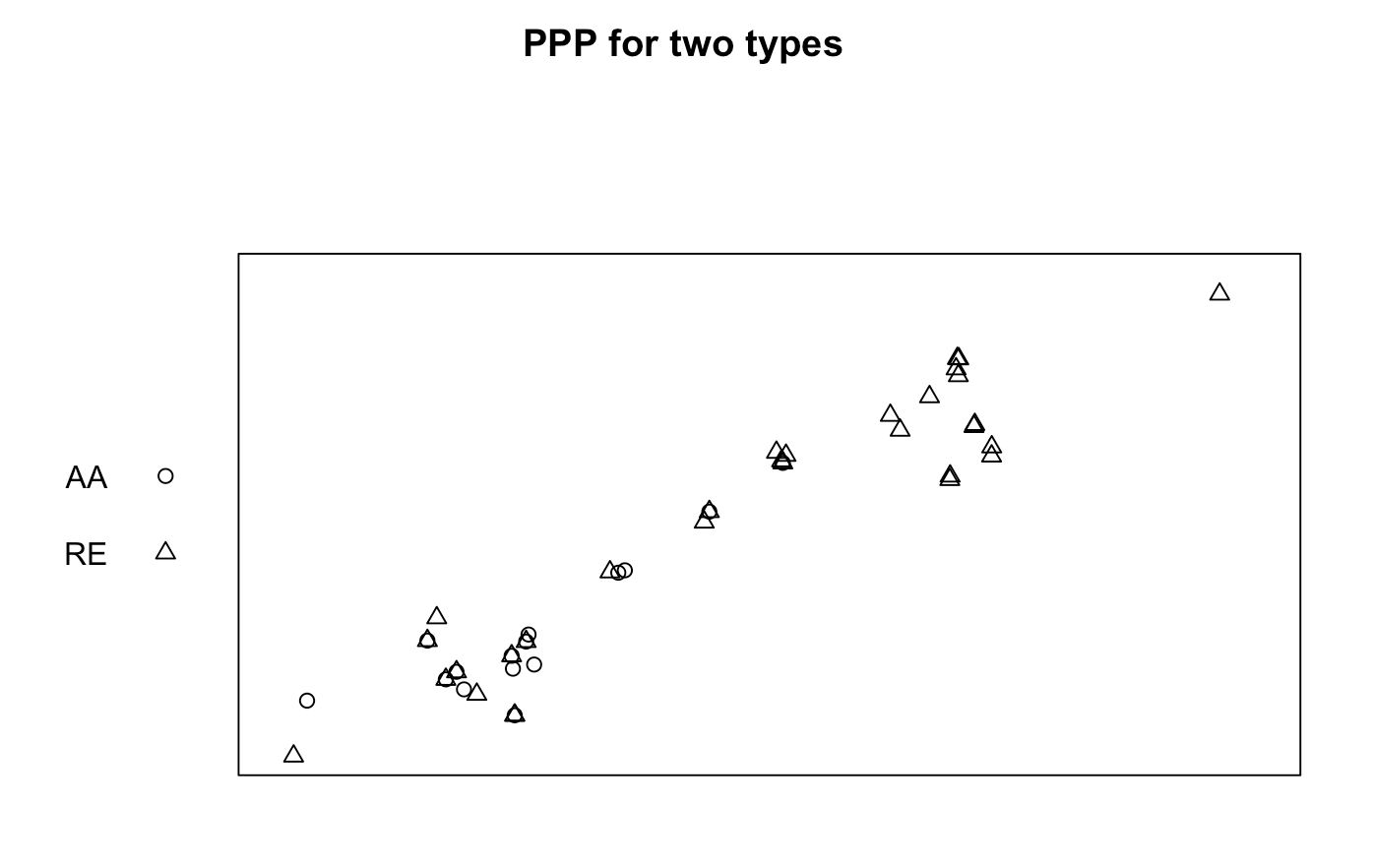
I'm having trouble interpreting the results I got from relrisk. My data is a multiple point process containing two marks (two rodents species AA and RE), I want to know if they are spatially segregated or not.
> summary(REkm)
Marked planar point pattern: 46 points
Average intensity 0.08101444 points per square unit
*Pattern contains duplicated points*
Coordinates are given to 3 decimal places
i.e. rounded to the nearest multiple of 0.001 units
Multitype:
frequency proportion intensity
AA 15 0.326087 0.02641775
RE 31 0.673913 0.05459669
Window: rectangle = [4, 38] x [0.3, 17] units
x 16.7 units)
Window area = 567.8 square units
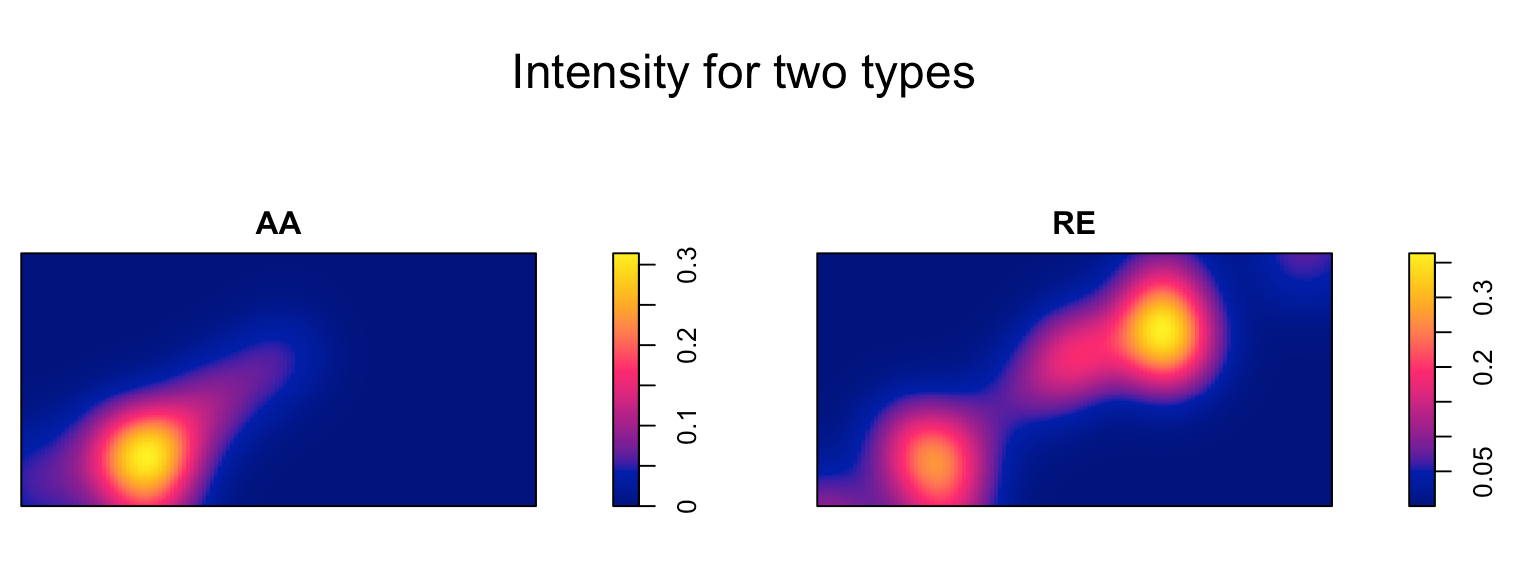
relkm <- relrisk(REkm)
plot(relkm, main="Relrisk default")
 The bandwidth of this
The bandwidth of this relrisk estimation is automatically selection by default(bw.relrisk), but when I tried other numeric number using sigma= 0.5 or 1, the results are somehow kind of weird.
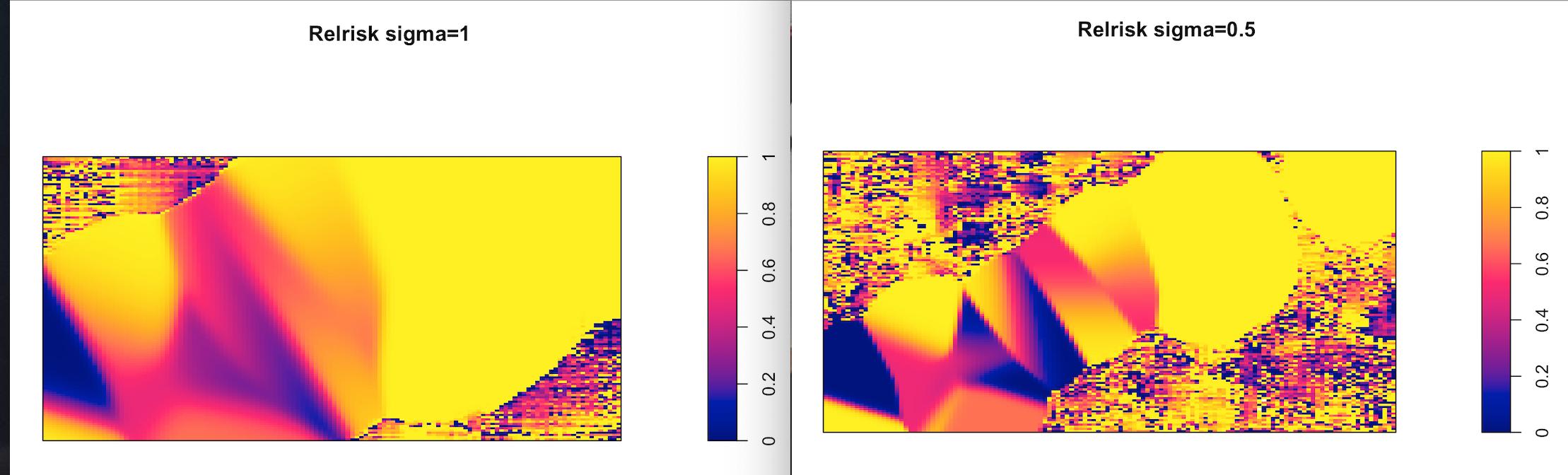 How did this happened? Was it because the large proportion of blank space of my ppp?
How did this happened? Was it because the large proportion of blank space of my ppp?
According to chapter.14 of Spatial Point Patterns books and the previous discussion, I assume the default of relrisk will show the ratio of intensities (case divided by control, in my case: RE divided by AA), but if I set casecontrol=FALSE, I can get the spatially-varying probability of each type.
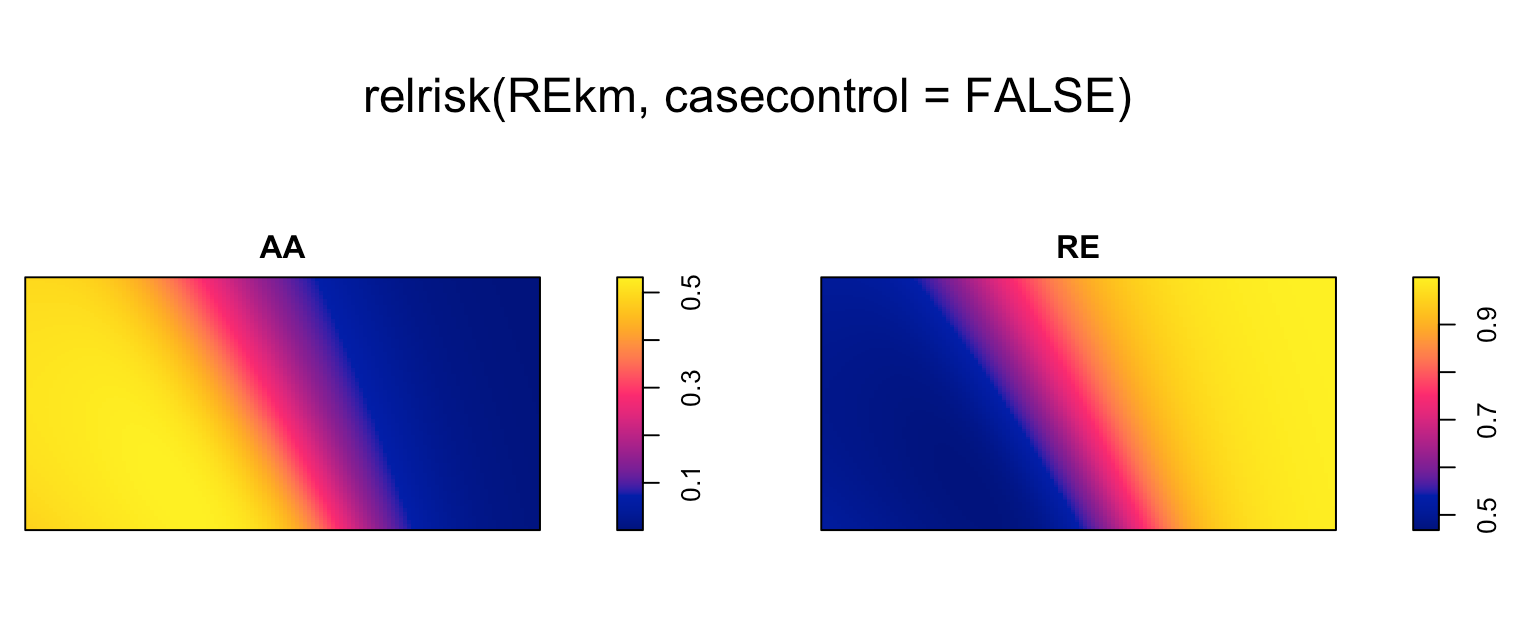 Then why the image of type RE in the
Then why the image of type RE in the Casecontrol=False looks exactly same as the relrisk estimation by default? Or they both estimate p(RE)=λRE/ λRE λAA for each sites?
Any help will be appreciated! Thanks a lot!
CodePudding user response:
That's two questions.
- Why does the image for
REwhencasecontrol=FALSElook the same as the default output fromrelrisk?
The definitive source of information about spatstat functions is the online documentation in the help files. The help file for relrisk.ppp gives full details of the behaviour of this function. It says that the calculation of probabilities and risks is controlled by the argument relative. If relative=FALSE (the default), the code calculates the spatially varying probability of each type. If relative=TRUE it calculates the relative risk of each type i, defined as the ratio of the probability of type i to the probability of type c where c is the type designated as the control. If you wanted the relative risk then you should set relative=TRUE.
- Very different results obtained when setting
sigma=0.5compared to the automatically selected bandwidth.
Your example output says that the window is 34 by 17 units. A smoothing bandwidth of sigma=0.5 is very small for this region. Imagine each data point being replaced by a blurry circle of radius 0.5; there would be a lot of empty space. The smoothing procedure is encountering numerical problems which are causing the funky artefacts.
You could try a range of different values of sigma, say from 1 to 15, and decide which value produces the most satisfactory result.
The plot of relrisk(REkm, casecontrol=FALSE) suggests that the automatic bandwidth selector bw.relriskppp chose a much larger value of sigma, perhaps about 10. You can investigate this by
b <- bw.relriskppp(REkm)
print(b)
plot(b)
The print command will print the chosen value of sigma that was used in the default calculation. The plot command will show the cross-validation criterion which was maximised to select the bandwidth. This gives you an idea of the range of values of sigma that are acceptable according to the automatic selector.
Read the help file for bw.relriskppp about the different options available for bandwidth selection method. Maybe a different choice of method would give you a more acceptable result from your viewpoint.