Hi I would like to get the Jaccard similarity between all rows in a dataframe.
I already have a jaccard similarity function like the following which is taking in two lists, but I couldn't get my head around how you can keep track of the users for which the comparison is being done.
def jaccard_similarity(x,y):
""" returns the jaccard similarity between two lists """
intersection_cardinality = len(set.intersection(*[set(x), set(y)]))
union_cardinality = len(set.union(*[set(x), set(y)]))
return intersection_cardinality/float(union_cardinality)
I would like to run this function against all the rows in the dataframe.
| wordings | users |
|---|---|
| apple,banana,orange,pears | adeline |
| banana,jackfruit,berries,apple | ericko |
| berries,grapes,watermelon | mary |
How can I generate an output like the below where I can keep track of the users being compared?
| user1 | user2 | similarity |
|---|---|---|
| adeline | eriko | 0.5 |
| adeline | mary | 0.2 |
Thank you very much for guidance.
sentences = ['apple,banana,orange,pears', 'banana,jackfruit,berries,apple']
sentences = [sent.lower().split(",") for sent in sentences]
jaccard_similarity(sentences[0], sentences[1])
Output: 0.3333333333333333
Running the above code would makes me get the values that I wanted but I am just stuck on how to keep track of the users being compared in the dataframe if I were to have 100 rows of the data.
Thanks
CodePudding user response:
Possible solution is the following:
import itertools
import pandas as pd
# copied from OP above
def jaccard_similarity(x, y):
""" returns the jaccard similarity between two lists """
intersection_cardinality = len(set.intersection(*[set(x), set(y)]))
union_cardinality = len(set.union(*[set(x), set(y)]))
return intersection_cardinality/float(union_cardinality)
# set initial data and create dataframe
data = {"wordings": ["apple,banana,orange,pears", "banana,jackfruit,berries,apple", "berries,grapes,watermelon"], "users": ["adeline", "ericko", "mary"]}
df = pd.DataFrame(data)
# create list of tuples like [(wording, user), (wording, user)]
wordings_users = list(zip(df["wordings"], df["users"]))
result = []
# create list of all possible combinations between sets of (wording, user) and loop through them
for item in list(itertools.combinations(wordings_users, 2)):
similarity = jaccard_similarity(item[0][0], item[1][0])
data = {"user1": item[0][1], "user2": item[1][1], "similarity": similarity}
result.append(data)
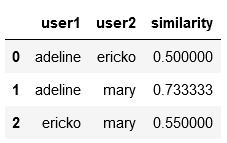
df1 = pd.DataFrame(result)
df1
Returns