I have a dataframe like this
| ID | Performed Time | Reported Time |
|---|---|---|
| 101 | 13:05. | 15.02. |
| 121 | 14.05. | 16.10. |
| 101 | 14.20. | 15.02. |
I want to filer rows if the ID and the Reported Time are the same. ie the resultant dataframe should be
| ID | Reported Time |
|---|---|
| 101 | 15.02. |
| 121 | 16.10. |
I tried using groupby to no avail.
CodePudding user response:
Please check this ticket:
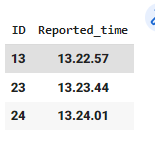
CodePudding user response:
You just need distinct():
>>> from datar.all import f, tibble, distinct
>>> df = tibble(
... ID=[101, 121, 101],
... **{
... "Performed Time": ["13:05.", "14.05.", "14.20."],
... "Reported Time": ["15.02.", "16.10.", "15.02."]
... }
... )
>>>
>>> df >> distinct(f.ID, f["Reported Time"])
ID Reported Time
<int64> <object>
0 101 15.02.
1 121 16.10.
I am the author of datar, the grammar of data manipulation in python, which wraps pandas APIs, and also with modin support now.
CodePudding user response:
df[["ID", "Reported Time"]].drop_duplicates()