I would like to combine a part of the columns from the dataframe with another part on the principle given in the screenshot. I have tried the pd.concat, pd.merge functions but I can't adjust them this way. Below I am posting a portion of the dataframe. The target I would like is that when there is a result in both parts it will select one of them based on the condition.
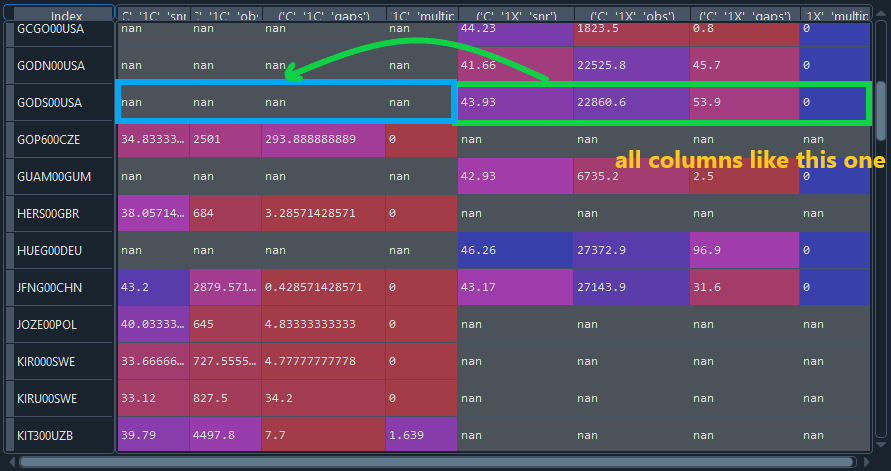
('C1Cs') ('C1Co') ('C1Cg') ('C1Cmp') ('C1Xs') ('C1Xobs') ('C1Xg') ('C1Xmp')
HERS00GBR 38.05 684.0 3.2 0.0 Nan Nan Nan Nan
HUEG00DEU Nan Nan Nan Nan 46.26 27372.9 96.9 0.0
JFNG00CHN 43.19 2879.5 0.4 0.0 43.17 27143.9 31.6 0.0
JOZE00POL 40.03 645.0 4.8 0.0 Nan Nan Nan Nan
KIR000SWE 33.66 727.5 4.7 0.0 Nan Nan Nan Nan
KIRU00SWE 33.12 827.5 34.2 0.0 Nan Nan Nan Nan
CodePudding user response:
One option is to combine_first (or fillna) the left part with the right part.
For this you need to slice and rename the right-hand columns:
half = len(df.columns)//2
rename_dic = dict(zip(df.columns[half:], df.columns[:half]))
out = df.iloc[:, :half].combine_first(df.iloc[:, half:].rename(columns=rename_dic))
output:
('C1Cs') ('C1Co') ('C1Cg') ('C1Cmp')
HERS00GBR 38.05 684.0 3.2 0.0
HUEG00DEU 46.26 27372.9 96.9 0.0
JFNG00CHN 43.19 2879.5 0.4 0.0
JOZE00POL 40.03 645.0 4.8 0.0
KIR000SWE 33.66 727.5 4.7 0.0
KIRU00SWE 33.12 827.5 34.2 0.0
NB. first thing, ensure the NaNs are real NaNs and not 'Nan' strings: df = df.replace('Nan', float('nan'))
If you want in place modification of your dataframe (i.e. no output but modifying your input dataframe directly), @JonClements suggested a nice alternative with update and set_axis:
df.update(df.iloc[:, -4:].set_axis(df.columns[:4], axis=1), overwrite=False)