Currently my dataset is as:
| ID | value |
|---|---|
| 1 | str1/value1,str2/value21,value22,value23,str3/value31,value32 |
| 2 | str4/value4,str5/value51,value52,value53,str6/value61,value62 |
I want to first split data on a comma (',') and then on the ('/'), but I want to keep all the occurrences after '/' with a comma. Also, I need to split them into row values.
The output should be:
| ID | str | value |
|---|---|---|
| 1 | str1 | value1 |
| 1 | str2 | value21,value22,value23 |
| 1 | str3 | value31,value32 |
| 2 | str4 | value4 |
| 2 | str5 | value51,value52,value53 |
| 2 | str6 | value61,value62 |
Please can somebody help me do it in an efficient way, instead of looping it for each and every occurrence.
CodePudding user response:
IIUC, you could use a double split with a regex:
df['str'] = df['value'].str.split(r',(?=[^/,] /)')
df = df.explode('str')
df[['str', 'value']] = df['str'].str.split('/', expand=True)
output:
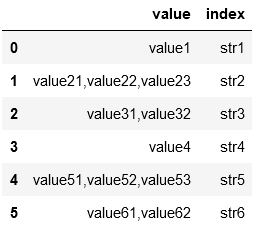
ID value str
0 1 value1 str1
0 1 value21,value22,value23 str2
0 1 value31,value32 str3
1 2 value4 str4
1 2 value51,value52,value53 str5
1 2 value61,value62 str6
Or, generating a new dataframe, with extractall and named capturing groups a join:
df2 = (df[['ID']]
.join(df['value']
.str.extractall(r'(?P<str>[^,/] )/(?P<value>[^/] ?)(?=,[^,] /|$)')
.droplevel(1))
)
output:
ID str value
0 1 str1 value1
0 1 str2 value21,value22,value23
0 1 str3 value31,value32
1 2 str4 value4
1 2 str5 value51,value52,value53
1 2 str6 value61,value62