I'm using beautifulsoup and selenium to scrape some data in python. Here is my code which I run through the url https://www.flashscore.co.uk/match/YwbnUyDn/#/match-summary/point-by-point/10:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
DRIVER_PATH = '$PATH/chromedriver.exe'
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, executable_path=DRIVER_PATH)
class_name = "matchHistoryRow__dartThrows"
def write_to_output(url):
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'html.parser')
print(soup.find_all("div", {"class": class_name}))
return
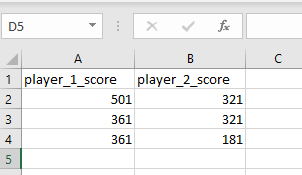
This is the schema I am trying to scrape- I would like to get the pair of spans between the colons and put them into separate columns on a csv, the problem is the class comes either before or after the colon, so I'm not sure how to go about doing this. For example:
<div ><span><span >321</span>:<span>501</span>
<span title="180 thrown">180</span></span>, <span><span>321</span>:<span
>361</span><span
title="140 thrown">140 </span></span>, <span><span
>224</span>:<span>361</span></span></div>
I'd like this to be represented this way in a csv:
player_1_score,player_2_score
321,501
321,361
224,361
What's the best way to go about this?
CodePudding user response:
You can use regex to parse the scores (the easiest method, if the text is structured accordingly):
import re
import pandas as pd
from bs4 import BeautifulSoup
html_doc = """
<div ><span><span >321</span>:<span>501</span>
<span title="180 thrown">180</span></span>, <span><span>321</span>:<span
>361</span><span
title="140 thrown">140 </span></span>, <span><span
>224</span>:<span>361</span></span></div>
"""
soup = BeautifulSoup(html_doc, "html.parser")
# 1. parse whole text from a row
txt = soup.select_one(".matchHistoryRow__dartThrows").get_text(
strip=True, separator=" "
)
# 2. find scores with regex
scores = re.findall(r"(\d )\s :\s (\d )", txt)
# 3. create dataframe from regex
df = pd.DataFrame(scores, columns=["player_1_score", "player_2_score"])
print(df)
df.to_csv("data.csv", index=False)
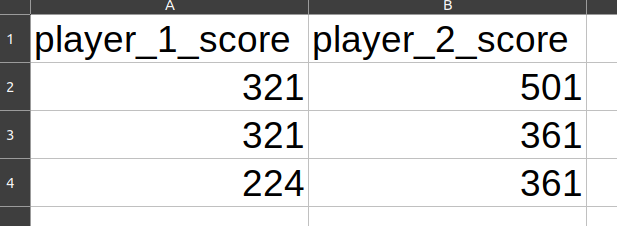
Prints:
player_1_score player_2_score
0 321 501
1 321 361
2 224 361
This crates data.csv (screenshot from LibreOffice):
Another method, without using re:
scores = [
s.get_text(strip=True)
for s in soup.select(
".matchHistoryRow__dartThrows > span > span:nth-of-type(1), .matchHistoryRow__dartThrows > span > span:nth-of-type(2)"
)
]
df = pd.DataFrame(
{"player_1_score": scores[::2], "player_2_score": scores[1::2]}
)
print(df)
CodePudding user response:
Using Selenium and