For the image seen, I want to filter the data values from 'Seller id' to 'Membership'. But there is no fixed set of row values to do filtering. For ex, if all the data values are of 10 entries its fine but the scenario here is diff one set has 10 entries and the second set has 13 entries. there is no fixed set of row vales foe each seller_id's.
Can you help me with filtering this using a python for loop.
Open for suggestions too!
Thanks in advance!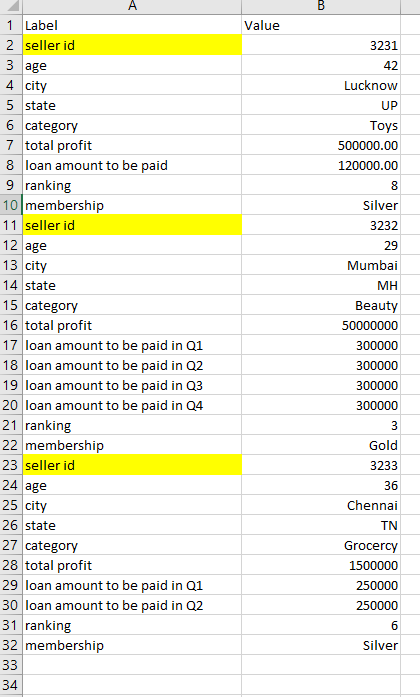
For the image seen, I want to filter the data values from 'Seller id' to 'Membership'. But there is no fixed set of row values to do filtering. For ex, if all the data values are of 10 entries its fine but the scenario here is diff one set has 10 entries and the second set has 13 entries. there is no fixed set of row vales foe each seller_id's.
CodePudding user response:
If there are seller id values for start each group use:
df = pd.read_excel('sales.xlsx', sheet_name='Sheet2')
#replace substring with regex ^ for start of string and $ for end of string
df['Label'] = df['Label'].str.strip(': ').replace({'</b>':''}, regex=True)
print (df.head())
Label Value
0 seller id 123459876
1 Seller failed verification check on the follow... ABC
2 Marketplace Id 1
3 Distributor Id INFLW
4 Brand AirASIA
#create groups by compare values (each group starting by seller id) with cumulative sum
for i, g in df.groupby(df['Label'].eq('seller id').cumsum()):
print (i)
print (g)
EDIT: Solution with compare original values, need </b>seller id</b> : instead seller id:
df = pd.read_excel('sales.xlsx', sheet_name='Sheet2')
print (df.head())
Label Value
0 </b>seller id</b> 123459876
1 </b>Seller failed transparency check on the fo... ABC
2 </b>Marketplace Id</b> 1
3 </b>Distributor Id</b> INFLW
4 </b>Brand</b> AirASIA
#changed seller id to </b>seller id</b>
for i, g in df.groupby(df['Label'].eq('</b>seller id</b> :').cumsum()):
print (i)
print (g)