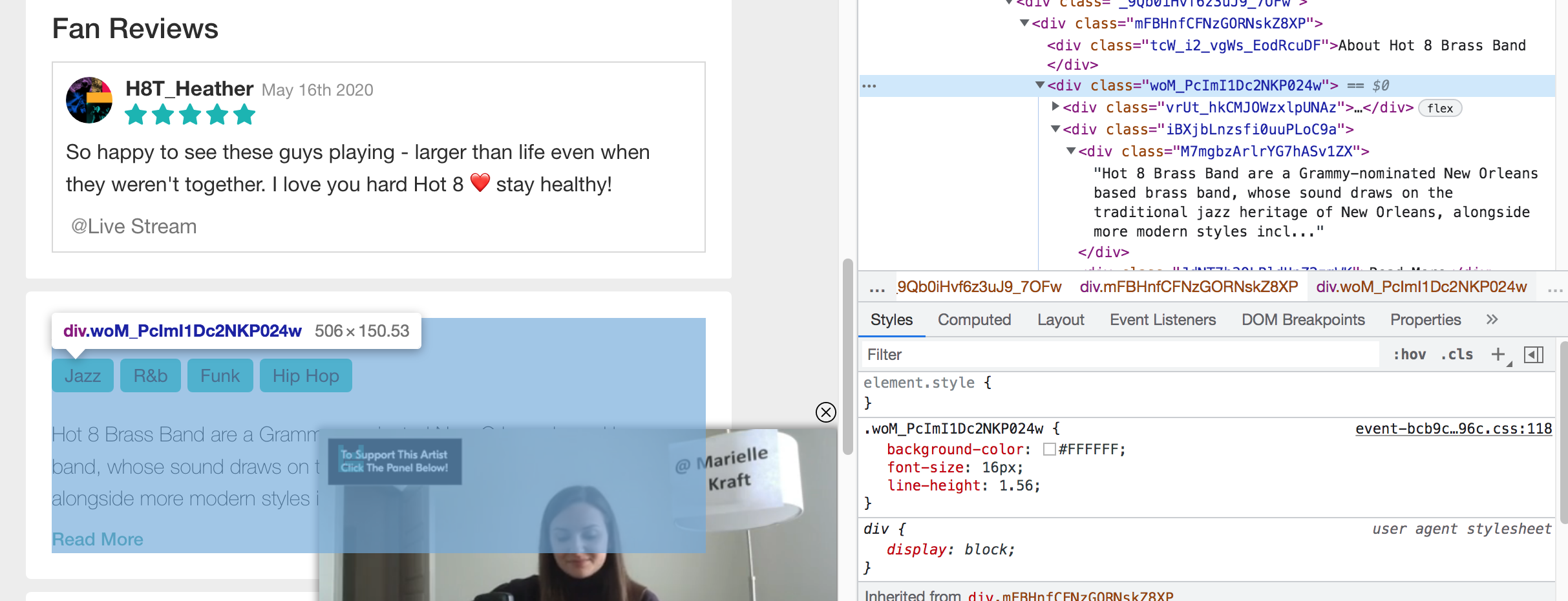
I'm trying to get information from this URL:
CodePudding user response:
I think the problem is with the XPATH you used to find the bio.
A few things you could consider for your future projects:
- Use
driver.find_element(By.CSS_SELECTOR, 'CSS_SELECTOR_GOES_HERE')ordriver.find_element(By.XPATH, 'XPATH_GOES_HERE')sincefind_elements_by_xpathandfind_elements_by_css_selectorare deprecated- Use
WebDriverWaitto allow enough time for elements to be loaded- You could also use
normalize-space()while matching text in xpath as it takes care of leading or trailing spacesThis code should work for you:
from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.common.exceptions import TimeoutException, NoSuchElementException from selenium.webdriver.chrome.options import Options from time import sleep options = Options() options.add_argument("--disable-notifications") driver = webdriver.Chrome(executable_path='D://chromedriver/100/chromedriver.exe', options=options) wait = WebDriverWait(driver, 20) url = "https://www.bandsintown.com/e/1024477910-hot-8-brass-band-at-the-howlin'-wolf?came_from=253&utm_medium=web&utm_source=city_page&utm_campaign=event" driver.get(url) try: # with xpath # artist = wait.until(EC.presence_of_element_located((By.XPATH, '//h1[contains(@href, "https://www.bandsintown.com/a")]'))).text artist = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'h1[href^="https://www.bandsintown.com/a/"]'))).text # read more wait.until(EC.presence_of_element_located((By.XPATH, '//div[normalize-space()="Read More"]'))).click() # bio bio = wait.until(EC.presence_of_element_located((By.XPATH, f'//div[normalize-space()="About {artist}"]/following-sibling::div/div[2]/div'))).text print(f'Artist: {artist}\nBio:\n{bio}') except Exception as ex: print(f"Error: {ex})CodePudding user response:
To extract the text ...Hot 8 Brass Band are a Grammy-nominated New Orleans based brass band, whose sound... ... you can use either of the following locator strategies:
Using xpath and text attribute:
driver.get("https://www.bandsintown.com/e/1024477910-hot-8-brass-band-at-the-howlin'-wolf?came_from=253&utm_medium=web&utm_source=city_page&utm_campaign=event") print(driver.find_element(By.XPATH, "//div[@id='main']//div[text()='About Hot 8 Brass Band']//following-sibling::div[1]//div/div[contains(., 'Hot 8 Brass Band')]").text)
Ideally you need to induce WebDriverWait for the visibility_of_element_located() and you can use either of the following locator strategies:
Using XPATH and
get_attribute("innerHTML"):driver.get("https://www.bandsintown.com/e/1024477910-hot-8-brass-band-at-the-howlin'-wolf?came_from=253&utm_medium=web&utm_source=city_page&utm_campaign=event") print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[@id='main']//div[text()='About Hot 8 Brass Band']//following-sibling::div[1]//div/div[contains(., 'Hot 8 Brass Band')]"))).get_attribute("innerHTML"))Console Output:
Hot 8 Brass Band are a Grammy-nominated New Orleans based brass band, whose sound draws on the traditional jazz heritage of New Orleans, alongside more modern styles incl...Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as ECYou can find a relevant discussion in How to retrieve the text of a WebElement using Selenium - Python