I am trying to implement logistic regression from scratch using numpy. I wrote a class with the following methods to implement logistic regression for a binary classification problem and to score it based on BCE loss or Accuracy.
def accuracy(self, true_labels, predictions):
"""
This method implements the accuracy score. Where the accuracy is the number
of correct predictions our model has.
args:
true_labels: vector of shape (1, m) that contains the class labels where,
m is the number of samples in the batch.
predictions: vector of shape (1, m) that contains the model predictions.
"""
counter = 0
for y_true, y_pred in zip(true_labels, predictions):
if y_true == y_pred:
counter =1
return counter/len(true_labels)
def train(self, score='loss'):
"""
This function trains the logistic regression model and updates the
parameters based on the Batch-Gradient Descent algorithm.
The function prints the training loss and validation loss on every epoch.
args:
X: input features with shape (num_features, m) or (num_features) for a
singluar sample where m is the size of the dataset.
Y: gold class labels of shape (1, m) or (1) for a singular sample.
"""
train_scores = []
dev_scores = []
for i in range(self.epochs):
# perform forward and backward propagation & get the training predictions.
training_predictions = self.propagation(self.X_train, self.Y_train)
# get the predictions of the validation data
dev_predictions = self.predict(self.X_dev, self.Y_dev)
# calculate the scores of the predictions.
if score == 'loss':
train_score = self.loss_function(training_predictions, self.Y_train)
dev_score = self.loss_function(dev_predictions, self.Y_dev)
elif score == 'accuracy':
train_score = self.accuracy((training_predictions== 1).squeeze(), self.Y_train)
dev_score = self.accuracy((dev_predictions== 1).squeeze(), self.Y_dev)
train_scores.append(train_score)
dev_scores.append(dev_score)
plot_training_and_validation(train_scores, dev_scores, self.epochs, score=score)
after testing the code with the following input
model = LogisticRegression(num_features=X_train.shape[0],
Learning_rate = 0.01,
Lambda = 0.001,
epochs=500,
X_train=X_train,
Y_train=Y_train,
X_dev=X_dev,
Y_dev=Y_dev,
normalize=False,
regularize = False,)
model.train(score = 'loss')
i get the following results
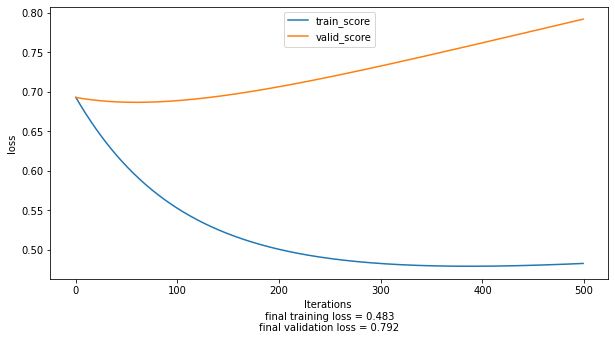
however when i swap the scoring metric to measure over time from loss to accuracy ass follows model.train(score='accuracy') i get the following result:
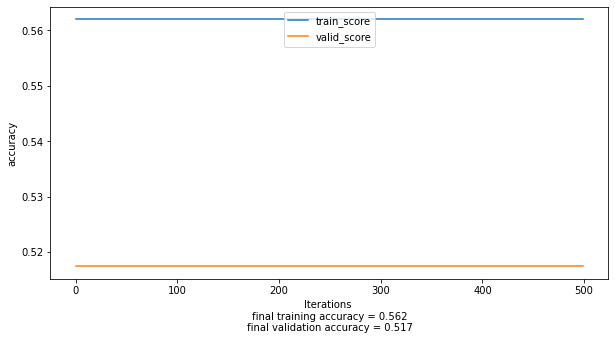 I have removed normalization and regularization to make sure i am using a simple implementation of logistic regression.
I have removed normalization and regularization to make sure i am using a simple implementation of logistic regression.
Note that i use an external method to visualize the training/validation score overtime in the LogisticRegression.train() method.
CodePudding user response:
The trick you are using to create your predictions before passing into the accuracy method is wrong. You are using (dev_predictions== 1).
Your problem statement is a Logistic Regression model that would generate a value between 0 and 1. Most of the times, the values will NOT be exactly equal to 1.
So essentially, every time you are passing a bunch of False or 0 to the accuracy function. I bet if you check the number of classes in your datasets having the value False or 0 would be :
- exactly 51.7 % in validation dataset
- exactly 56.2 % in training dataset.
To fix this, you can use a in-between threshold like 0.5 to generate your labels. So use something like dev_predictions>0.5