I have created a dataframe called df as follows:
import pandas as pd
d = {'feature1': [1, 22,45,78,78], 'feature2': [33, 2,2,65,65], 'feature3': [100, 2,359,87,2],}
df = pd.DataFrame(data=d)
print(df)
The dataframe looks like this:
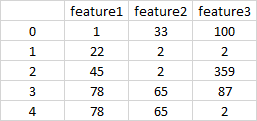
I want to create two new columns called Freq_1 and Freq_2 that count, for each record, how many times the number 1 and number 2 appear respectively. So, I'd like the resulting dataframe to look like this:
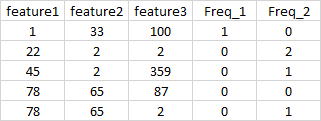
So, let's take a look at the column called Freq_1:
- for the first record, it's equal to 1 because the number
1appears only once across the whole first record; - for the other records, it's equal to 0 because the number
1never appears.
Let's take a look now at the column called Freq_2:
- for the first record, Freq_2 is equal to 0 because number
2doesn't appear; - for second record, Freq_2 is equal to 2 because the number
2appears twice; - and so on ...
How do I create the columns Freq_1 and Freq_2 in pandas?
CodePudding user response:
Try this:
freq = {
i: df.apply(lambda col: col.eq(i)).sum(axis=1)
for i in range(10)
}
pd.concat([df, pd.DataFrame(freq).add_prefix("Freq_")], axis=1)
Result:
feature1 feature2 feature3 Freq_0 Freq_1 Freq_2 Freq_3 Freq_4 Freq_5 Freq_6 Freq_7 Freq_8 Freq_9
1 33 100 0 1 0 0 0 0 0 0 0 0
22 2 2 0 0 2 0 0 0 0 0 0 0
45 2 359 0 0 1 0 0 0 0 0 0 0
78 65 87 0 0 0 0 0 0 0 0 0 0
78 65 2 0 0 1 0 0 0 0 0 0 0
CodePudding user response:
String pattern matching can be performed when the columns are casted to string columns.
d = {'feature1': [1, 22,45,78,78], 'feature2': [33, 2,2,65,65], 'feature3': [100, 2,359,87,2],}
df = pd.DataFrame(data=d)
df = df.stack().astype(str).unstack()
Now we can iterate for each pattern that we are looking for:
usefull_columns = df.columns
for pattern in ['1', '2']:
df[f'freq_{pattern}'] = df[usefull_columns].stack().str.count(pattern).unstack().max(axis=1)
Printing the output:
feature1 feature2 feature3 freq_1 freq_2
0 1 33 100 1.0 0.0
1 22 2 2 0.0 2.0
2 45 2 359 0.0 1.0
3 78 65 87 0.0 0.0
4 78 65 2 0.0 1.0
CodePudding user response:
We can do
s = df.where(df.isin([1,2])).stack()
out = df.join(pd.crosstab(s.index.get_level_values(0),s).add_prefix('Freq_')).fillna(0)
Out[299]:
feature1 feature2 feature3 Freq_1.0 Freq_2.0
0 1 33 100 1.0 0.0
1 22 2 2 0.0 2.0
2 45 2 359 0.0 1.0
3 78 65 87 0.0 0.0
4 78 65 2 0.0 1.0