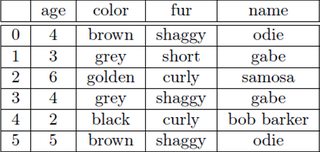
I'm given the following DataFrame, and I want get the most common color among dogs. I have started by making this table in python as a DataFrame:
import pandas as pd
table = {
"age" : [4,3,6,4,2,5],
"color" : ["brown","grey","golden","grey","black","brown"],
"fur" : ["shaggy","short","curly","shaggy","curly","shaggy"],
"name" : ["odie","gabe","samosa","gabe","bob marker","odie"]
};
df = pd.DataFrame(table);
Then I have grouped by column color and counted the amount of each occuring color in descending order, such that the first row has the most occuring / common color among dogs.
df = df.groupby("color").color.agg(["count"]).sort_values(["count"],ascending=False);
At this point, the DataFrame df looks like that:
count
color
brown 2
grey 2
black 1
golden 1
Now to actually print out the most common color among dogs, I have done this:
print(df[df["count"]==df["count"].max()].index);
Where index is the color.
Final output:
Index(['brown', 'grey'], dtype='object', name='color')
Would you say the way I print it out is correct to the question? And isn't there an easier way to do this with pandas? It feels like I did it too complicated and it can be done faster :/
CodePudding user response:
You could use value_counts:
counts = df['color'].value_counts()
out = counts[counts==counts.max()].index.tolist()
You could use pipe to chain these two lines into a one-liner:
out = df['color'].value_counts().pipe(lambda x: x[x==x.max()].index).tolist()
Output:
['brown', 'grey']