I have two different csv files that correspond to a person's HRV (csv no1) and their emotions (csv no2). The first dataset used UNIX timestamps to capture the HRV values and the other recorded the person's emotions while they were watching themselves every 5 seconds.
Since the emotions are captured every five seconds and the HRV values are captured every second, I want to iterate through the rows of the HRV values dataset and create a new one (or just a new column, whatever works) that contains the average sum of each set of 5 rows. For example the mean value of the first 5 rows corresponds to that emotion, the next 5 rows correspond to that other emotion etc.
I want to do that so I can eventually be able to link them with each other.
Any ideas on how to do that?
Unfortunately, I am not able to provide an easily-reproduced code snippet since the dataset is not mine to share, however, I can point out with a few screenshots how my datasets look:
This is the dataset with the HRV values:
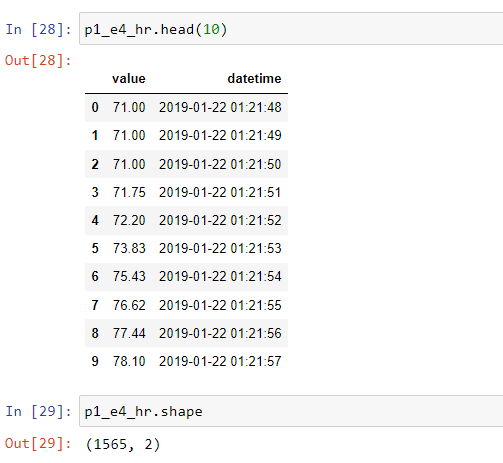
And this is the dataset with the emotion values:
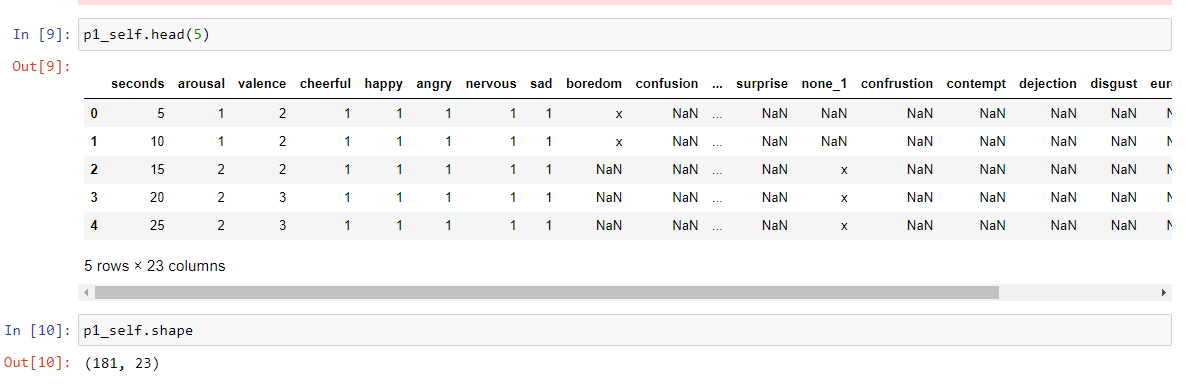
CodePudding user response:
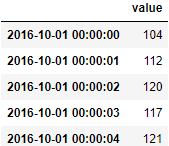
It would be good if you could provide data to test even if it is not real. I create data with the next code:
dates = pd.date_range('10-01-2016', periods=50, freq='S')
df = pd.DataFrame({'value': 100 np.random.randint(-5, 10, 50).cumsum()},index=dates)
df.head()
I think that 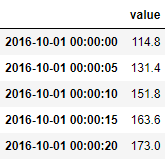
Note that in my example the timestamp is the index, also, I use the mean as the value to pass, but I don't really know what you would like to use. After this, you could just merge the data.