I have a dataframe like below. I want to convert it to pivot table format, where there is each row for unique ID, new column for each Score with Type prefix.
I have about 15 different Types in the actual dataframe.
df = pd.DataFrame({'ID' : [1,1,2,2,3,3,4,4],
'Type':['A','B','A','B','A','B','A','B'],
'Score':[0.3,np.nan, 0.2, 0.1, 1.1,np.nan, 2, np.nan]})
Desired output
| ID | A_Score | B_Score |
|---|---|---|
| 1 | 0.3 | |
| 2 | 0.2 | 0.1 |
| 3 | 1.1 | |
| 4 | 2 |
I tried below and it almost does what I need but I need the column renames and need it in pandas dataframe
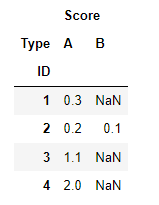
df2 = df.pivot_table(index=['ID'], columns='Type')
CodePudding user response:
You can do
out = df.pivot_table(index='ID', columns='Type',values='Score').add_prefix('Score_').reset_index()
Out[355]:
Type ID Score_A Score_B
0 1 0.3 NaN
1 2 0.2 0.1
2 3 1.1 NaN
3 4 2.0 NaN
CodePudding user response:
You can flatten your multiIndex header using map-join
df2.columns = df2.columns.map('_'.join)
print(df2)
Output:
Score_A Score_B
ID
1 0.3 NaN
2 0.2 0.1
3 1.1 NaN
4 2.0 NaN
CodePudding user response:
Another version:
df = df.set_index(["ID", "Type"]).unstack(1)
df.columns = [f"{b}_{a}" for a, b in df.columns]
print(df.reset_index().fillna(""))
Prints:
ID A_Score B_Score
0 1 0.3
1 2 0.2 0.1
2 3 1.1
3 4 2.0