I'm new to BS4 and I've read through all the similar questions. I'm trying to scrape a number from a sentence so that I can loop through all the pages. The sentence is, "Page 1 of 5" and I'm trying to get the number "5" and store it into a variable. However, I'm facing an error saying that AttributeError: 'NoneType' object has no attribute 'get_text'. Below is the HTML:
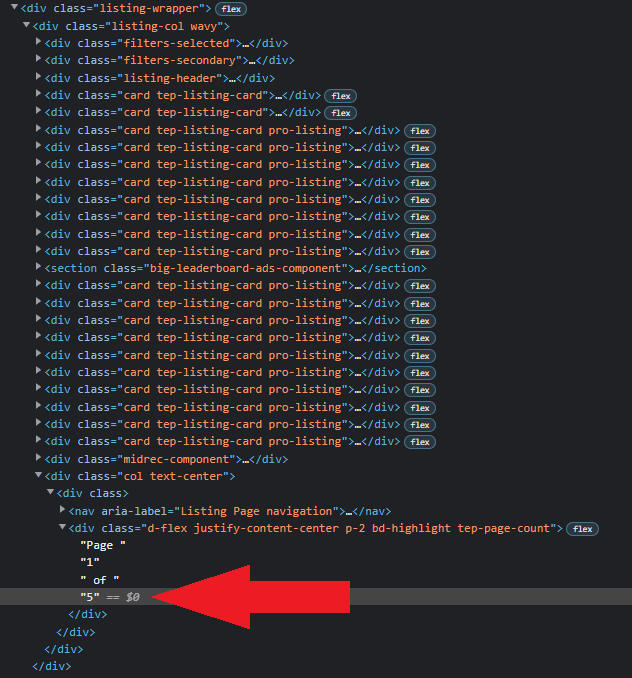
This is the code I tried.
from bs4 import BeautifulSoup
import requests
url = 'https://www.edgeprop.my/buy/kelantan/all-residential?page=1'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.79 Safari/537.36'}
page = requests.get(url, headers=headers)
soup = BeautifulSoup(page.content, 'html.parser')
total_pages = soup.find('div', class_="tep-page-count").get_text()
print(total_pages.strip())
Some try and error solution I have tried is by replacing the html.parser with lxml, replacing the class name with text-center, listing-col, wavy and listing-wrapper and neither both works.
CodePudding user response:
The data you see on the page is loaded from external URL via JavaScript (so beautifulsoup doesn't see it). To get total number of properties found you can use this example:
import json
import requests
url = "https://www.edgeprop.my/jwdsonic/api/v1/property/search?=&listing_type=sale&state=Kelantan&property_type=rl&start=0&size=20"
data = requests.get(url).json()
# uncomment to print all data:
# print(json.dumps(data, indent=4))
print("Total number of properties found:", data["found"])
Prints:
Total number of properties found: 84