I have the data about sales by years and by-products, let's say like this:
Year <- c(2010,2010,2010,2010,2010,2011,2011,2011,2011,2011,2012,2012,2012,2012,2012)
Model <- c("a","b","c","d","e","a","b","c","d","e","a","b","c","d","e")
Sale <- c("30","45","23","33","24","11","56","19","45","56","33","32","89","33","12")
df <- data.frame(Year, Model, Sale)
Firstly I need to calculate the "Share" column which represents the share of each product within each year.
After I compute cumulative share like this:
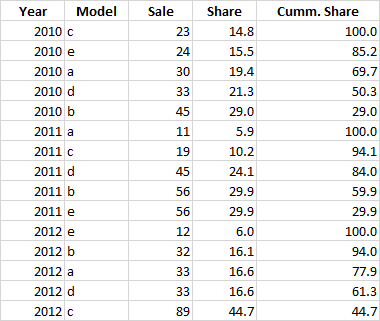
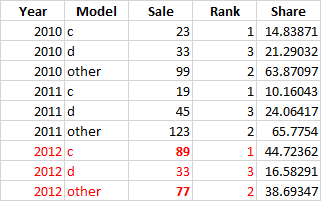
In the 3rd step need to identify products that accumulate total sales up to 70% in the last year (2012 in this case) and keep only these products in the whole dataframe add a ranking column (based on last year) and summarises all the rest of products as category "other". So the final dataframe should be like this:
CodePudding user response:
This is a fairly complex data wrangling task, but can be achieved using dplyr:
library(dplyr)
df %>%
mutate(Sale = as.numeric(Sale)) %>%
group_by(Year) %>%
mutate(Share = 100 * Sale/ sum(Sale),
Year_order = order(order(-Share))) %>%
arrange(Year, Year_order, by_group = TRUE) %>%
mutate(Cumm.Share = cumsum(Share)) %>%
ungroup() %>%
mutate(below_70 = Model %in% Model[Year == max(Year) & Cumm.Share < 70]) %>%
mutate(Model = ifelse(below_70, Model, 'Other')) %>%
group_by(Year, Model) %>%
summarize(Sale = sum(Sale), Share = sum(Share), .groups = 'keep') %>%
group_by(Year) %>%
arrange(Year, -Share, by_group = TRUE) %>%
ungroup() %>%
mutate(Rank = match(Model, Model[Year == max(Year)]))
#> # A tibble: 9 x 5
#> Year Model Sale Share Rank
#> <dbl> <chr> <dbl> <dbl> <int>
#> 1 2010 Other 102 65.8 2
#> 2 2010 a 30 19.4 3
#> 3 2010 c 23 14.8 1
#> 4 2011 Other 157 84.0 2
#> 5 2011 c 19 10.2 1
#> 6 2011 a 11 5.88 3
#> 7 2012 c 89 44.7 1
#> 8 2012 Other 77 38.7 2
#> 9 2012 a 33 16.6 3
Note that in the output this code has kept groups a and c, rather than c and d, as in your expected output. This is because a and d have the same value in the final year (16.6), and therefore either could be chosen.
Created on 2022-04-21 by the reprex package (v2.0.1)
CodePudding user response:
Year <- c(2010,2010,2010,2010,2010,2011,2011,2011,2011,2011,2012,2012,2012,2012,2012)
Model <- c("a","b","c","d","e","a","b","c","d","e","a","b","c","d","e")
Sale <- c("30","45","23","33","24","11","56","19","45","56","33","32","89","33","12")
df <- data.frame(Year, Model, Sale, stringsAsFactors=F)
years <- unique(df$Year)
shares <- c()
cumshares <- c()
for (year in years){
extract <- df[df$Year == year, ]
sale <- as.numeric(extract$Sale)
share <- 100*sale/sum(sale)
shares <- append(shares, share)
cumshare <- rev(cumsum(rev(share)))
cumshares <- append(cumshares, cumshare)
}
df$Share <- shares
df$Cumm.Share <- cumshares
df
gives
> df
Year Model Sale Share Cumm.Share
1 2010 a 30 19.354839 100.000000
2 2010 b 45 29.032258 80.645161
3 2010 c 23 14.838710 51.612903
4 2010 d 33 21.290323 36.774194
5 2010 e 24 15.483871 15.483871
6 2011 a 11 5.882353 100.000000
7 2011 b 56 29.946524 94.117647
8 2011 c 19 10.160428 64.171123
9 2011 d 45 24.064171 54.010695
10 2011 e 56 29.946524 29.946524
11 2012 a 33 16.582915 100.000000
12 2012 b 32 16.080402 83.417085
13 2012 c 89 44.723618 67.336683
14 2012 d 33 16.582915 22.613065
15 2012 e 12 6.030151 6.030151
I don't understand what you mean by step 3, how do you decide which products to keep?