I am trying to showcase how to generate PDF files from URL input using Lambda and Puppeteer. The problem is that the result returned to the client is blank PDF page.
The code of the generation is like below.
async function renderPdfFromUrl(url) {
let browser = null;
let pdfBuffer = null;
try {
browser = await chromium.puppeteer.launch({
args: chromium.args,
defaultViewport: chromium.defaultViewport,
executablePath: await chromium.executablePath,
headless: chromium.headless,
ignoreHTTPSErrors: true,
});
const page = await browser.newPage();
await page.goto(url, {
waitUntil: ['domcontentloaded', 'load', "networkidle0"]
});
//pdfBuffer = await page.content();
pdfBuffer = await page.pdf({
format: 'A4',
printBackground: true,
margin: {
top: '1cm',
right: '1cm',
bottom: '1cm',
left: '1cm',
},
});
} catch (error) {
console.log(error);
return null;
} finally {
if (browser !== null) {
await browser.close();
}
}
return pdfBuffer;
}
The return of the Lambda is like below.
return {
statusCode: 200,
headers: {
'Content-Type': 'application/pdf',
'Content-Length': pdfBuffer.length,
'X-Time-To-Render': `${timeToRenderMs}ms`,
},
body: pdfBuffer.toString('utf-8'),
};
You can find the full source code here. 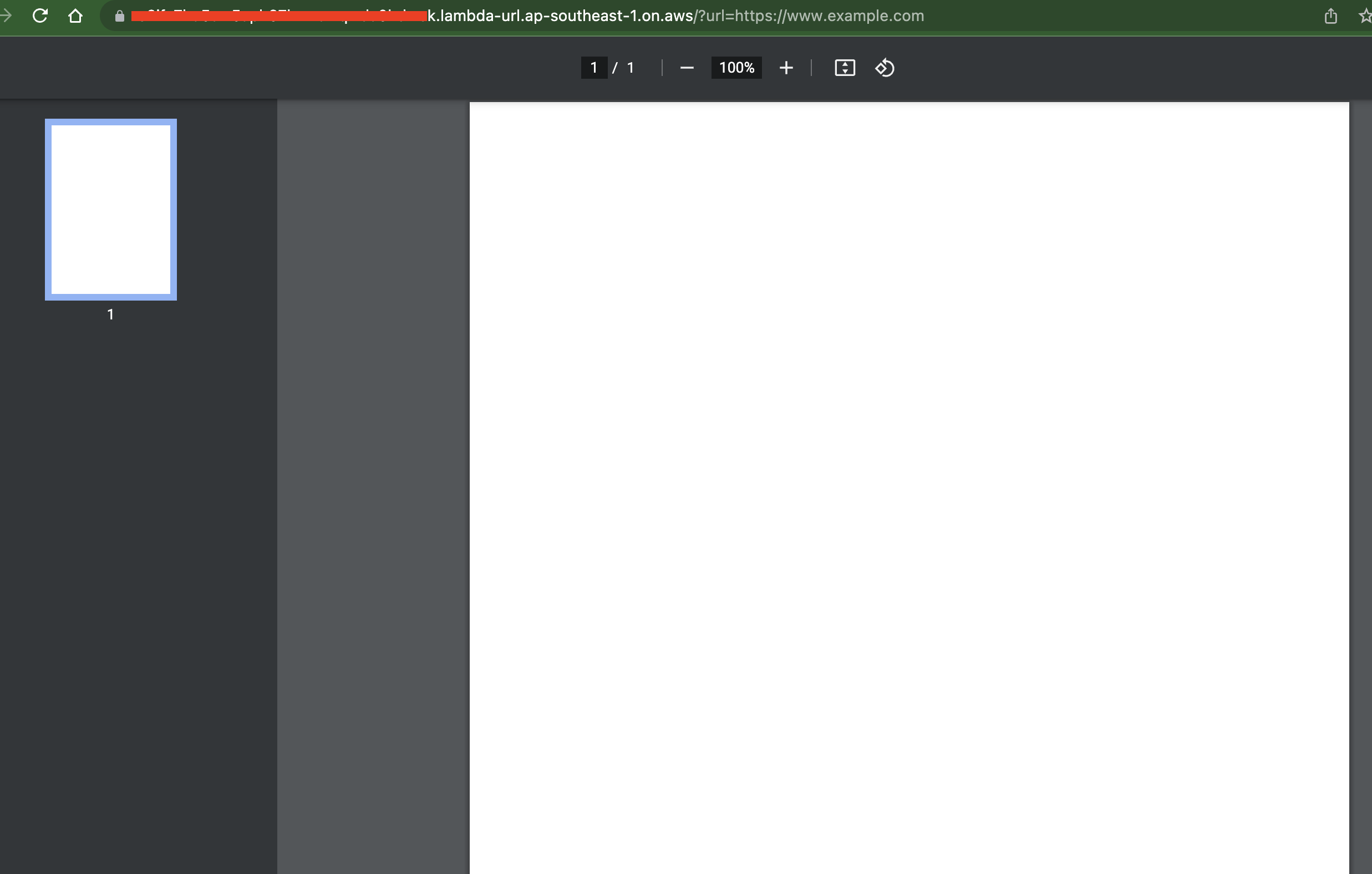
When I tried the page.content() instead of page.pdf(), the result shows that the HTML content is fetched.
<!DOCTYPE html><html><head>
<title>Example Domain</title>
<meta charset="utf-8">
<meta http-equiv="Content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
What did I miss?
UPDATE 1
I tried uploading the PDF to S3 and return the signed URL. It turns out the object is a not a blank PDF file.
async function uploadPdfToS3(pdf) {
const client = new S3Client({
apiVersion: '2006-03-01',
});
const bucket = process.env.TEMP_BUCKET_NAME;
const key = `${v4()}.pdf`;
console.log(`Uploading to: s3://${bucket}/${key}`);
const putCommand = new PutObjectCommand({
Body: pdf,
Bucket: bucket,
Key: key,
ContentType: 'application/pdf'
});
await client.send(putCommand);
The return code becomes
if (returnType == 'pdf') {
return {
statusCode: 200,
headers: {
'Content-Type': 'application/pdf',
'Content-Length': pdfBuffer.length,
'X-Time-To-Render': `${timeToRenderMs}ms`,
},
body: pdfBuffer,
};
} else if (returnType == 'url') {
const tempFileUrl = await uploadPdfToS3(pdfBuffer);
return {
statusCode: 200,
headers: {
'Content-Type': 'application/json',
'X-Time-To-Render': `${timeToRenderMs}ms`,
},
body: {
url: tempFileUrl,
}
};
}
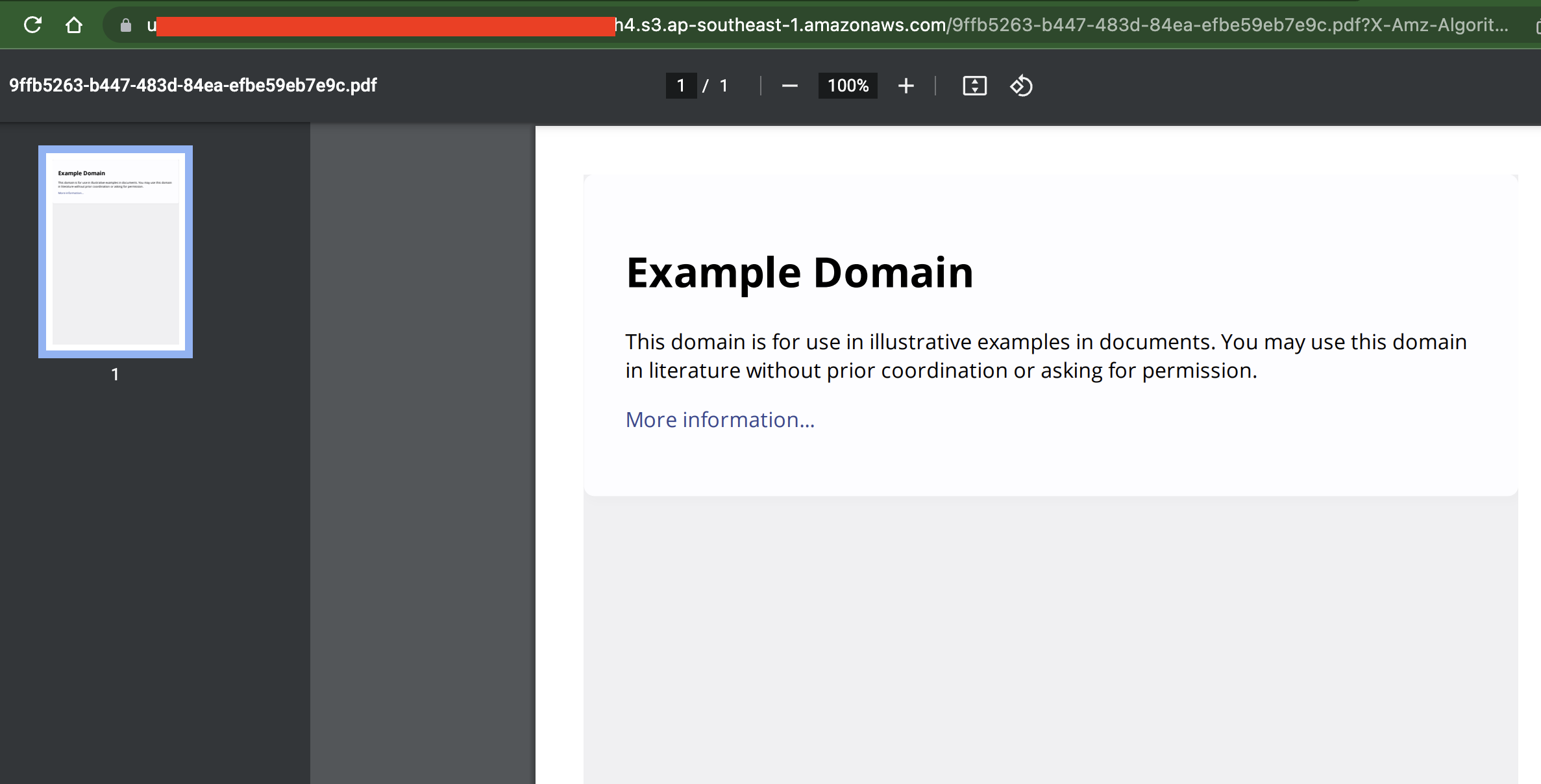
CodePudding user response:
first you store the file in server side and check pdf loads the content or not.
If pdf loads the content then convert it into base64 formate and access the frontend side.
const downloadAllPDF = async () => {
var bufferArray = base64ToArrayBufferAkash(response.data.data); // get the base64encoded response from backend side
var blobStore = new Blob([bufferArray], { type: "application/pdf" });
if (window.navigator && window.navigator.msSaveOrOpenBlob) {
window.navigator.msSaveOrOpenBlob(blobStore);
return;
}
var data = window.URL.createObjectURL(blobStore);
var link = document.createElement('a');
document.body.appendChild(link);
link.href = data;
link.download = "output.pdf";
link.click();
window.URL.revokeObjectURL(data);
link.remove();
}
const base64ToArrayBufferAkash = (data) => {
var bString = window.atob(data);
var bLength = bString.length;
var bytes = new Uint8Array(bLength);
for (var i = 0; i < bLength; i ) {
var ascii = bString.charCodeAt(i);
bytes[i] = ascii;
}
return bytes;
};
CodePudding user response:
Turns out the answer is pretty simple. We need to return as Base64. The return will be like below.
return {
statusCode: 200,
isBase64Encoded: true,
headers: {
'Content-Type': 'application/pdf',
'Content-Length': pdfBuffer.length,
'X-Time-To-Render': `${timeToRenderMs}ms`,
},
body: pdfBuffer,toString('base64'),
};