I am trying to port my C# common-crawl code to Node.js and getting error in with all HTTP libraries(node-fetch, axios of got) in getting the single page HTML from common-crawl S3 archive.
const offset = 994879995;
const length = 27549;
const offsetEnd = offset length 1;
const url = `https://data.commoncrawl.org/crawl-data/CC-MAIN-2018-43/segments/1539583511703.70/warc/CC-MAIN-20181018042951-20181018064451-00103.warc.gz`;
const response = await fetch(
url, //'https://httpbin.org/get',
{
method: "GET",
timeout: 10000,
compress: true,
headers: {
Range: `bytes=${offset}-${offsetEnd}"`,
'Accept-Encoding': 'gzip'
},
}
);
console.log(`status`, response.status);
console.log(`headers`, response.headers);
console.log(await response.text());
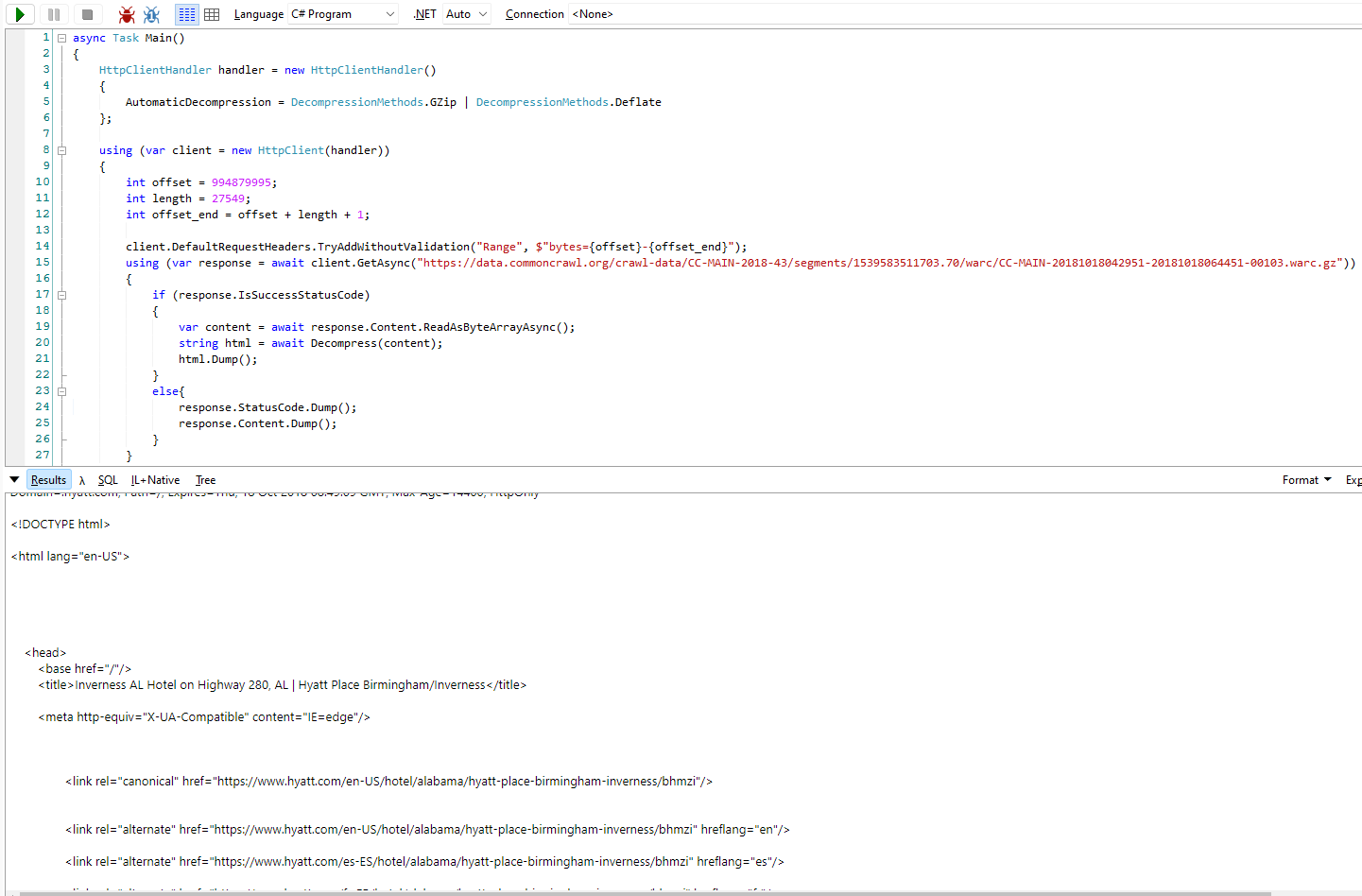
The status is 200, but none of the package able to read the body gzip body.

While my C# code is working fine to read the body as byte array and decompress it.
CodePudding user response:
The code below will fetch a single WARC record and extract the HTML payload. All status lines and headers (HTTP fetch of the WARC record, WARC record header, WARC record HTTP header) are logged as well as the HTML payload. The following points are changed:
the range header in the JS request includes a superfluous quotation mark. This caused actually that not a single WARC record was requested but the complete 1 GiB WARC file.
- see the response status code: 200 but should be 206 "Partial content"
- and also the "content-length" response header
- 10 seconds are maybe a too short timeout for fetching 1 GiB
the end offset should be
offset length - 1(instead of... 1): in the worst case the 2 extra bytes cause the gzip decompressor to thrown an exceptionbecause the WARC records are already gzip-compressed it does not make sense to request any HTTP-level compression
the gzipped WARC records needs to be uncompressed and parsed. Both is done by warcio - have a look at the excellent documentation of this module.
const fetch = require("node-fetch");
const warcio = require("warcio");
class WarcRecordFetcher {
async run() {
const offset = 994879995;
const length = 27549;
const offsetEnd = offset length - 1;
const url = `https://data.commoncrawl.org/crawl-data/CC-MAIN-2018-43/segments/1539583511703.70/warc/CC-MAIN-20181018042951-20181018064451-00103.warc.gz`;
const response = await fetch(
url, //'https://httpbin.org/get',
{
method: "GET",
timeout: 10000,
headers: {
Range: `bytes=${offset}-${offsetEnd}`
},
}
);
console.log(`status`, response.status);
console.log(`headers`, response.headers);
const warcParser = new warcio.WARCParser(response.body);
const warcRecord = await warcParser.parse();
console.log(warcRecord.warcHeaders.statusline);
console.log(warcRecord.warcHeaders.headers);
console.log(warcRecord.httpHeaders.statusline);
console.log(warcRecord.httpHeaders.headers);
const warcPayload = await warcRecord.contentText();
console.log(warcPayload)
}
}
new WarcRecordFetcher().run();