I have a pandas dataframe:
df = pd.DataFrame({'start': [50, 100, 50000, 50030, 100000],
'end': [51, 101, 50001, 50031, 100001],
'value': [1, 2, 3, 4, 5]},
index=['id1', 'id2', 'id3', 'id4', 'id5'])
>>> df
start end value
id1 50 51 1
id2 100 101 2
id3 50000 50001 3
id4 50030 50031 4
id5 100000 100001 5
Now I would like to extract groups of all rows within the size range of 150 in column "start". The output should look like:
group group_start group_end min_val max_value id_count
1 50 101 1 2 2
2 50000 50031 3 4 2
3 100000 100001 5 5 1
How to extract those groups?
CodePudding user response:
Use:
start = df['start'].iloc[0]
g = 0
gs = []
for val in df['start']:
print(val, start)
if val-start<150:
gs.append(g)
else:
g =1
start = val
gs.append(g)
df['g'] = gs
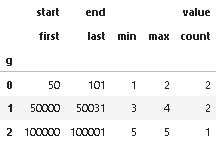
df.groupby('g').agg({'start': 'first', 'end': 'last', 'value':['min', 'max', 'count']})
Output:
CodePudding user response:
For range 150 is possible use integer division by 150 with factorize for groups starting by 1 and then aggregate columns by named aggregations, last add column group:
a = pd.factorize(df['start'] // 150)[0] 1
df = (df.groupby(a).agg(group_start = ('start','first'),
group_end = ('end','last'),
min_val = ('value','min'),
max_val = ('value','max'),
id_count=('value','size'))
.rename_axis('group')
.reset_index())
print (df)
group group_start group_end min_val max_val id_count
0 1 50 101 1 2 2
1 2 50000 50031 3 4 2
2 3 100000 100001 5 5 1
CodePudding user response:
df.reset_index(drop=True).groupby(np.arange(len(df)) // 2).agg(**{'min_val':('value','min'),'max_val':('value','max'),'id_count':('value','count')})