It has a start date and an end date. In the dataframe below, I want to extract data where the date of the "UPDATE DATE" item is between the start date and the end date or the "STUDY" item is unique.
STUDY Teacher UPDATE_DATE
0 math None -> A 2021-05-12
1 math A -> A, B 2021-09-23
2 math A, B -> A 2021-10-12
3 math A -> A, C 2022-02-25
4 science None -> A 2021-07-01
5 science A -> D 2021-09-09
6 science D -> D, B 2022-01-03
7 entertainment None -> C 2022-01-01
8 entertainment C -> B, C 2022-03-02
9 technology None -> E 2021-09-01
from_date = '2022-01-01'
to_date = '2022-04-10'
df['UPDATE_DATE']=pd.to_datetime(df['UPDATE_DATE'])
t = df['STUDY'].value_counts()
us = t[t==1].index.values
df = df.loc[(df['UPDATE_DATE'] >= from_date) & (df['UPDATE_DATE'] <= to_date)|(df['STUDY'].isin(us))]
output:
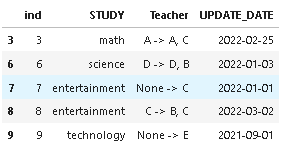
STUDY Teacher UPDATE_DATE
3 math A -> A, C 2022-02-25
6 science D -> D, B 2022-01-03
7 entertainment None -> C 2022-01-01
8 entertainment C -> B, C 2022-03-02
9 technology None -> E 2021-09-01
Next, Q.I want to split the value of the "Teacher" field based on the arrow and copy the row, I want to create an "INTERVAL_DAYS" field and add calculated values using the "UPDATE_DATE" item.
(ADD) -> Whenever the teacher of the study is changed, it is recorded in this dataframe. The final thing I want to find is the number of studies each Teacher is in charge of. One study is viewed as "1". So, taking math STUDY as an example, split the teacher based on the arrow, the number of teachers “A” from 2022-01-01 (start date) to 2022-02-25, 2022-02-25 to 2022- Until 04-10 (end date), I'm trying to obtain the counts in charge of teachers A and C. (* 2022-01-01 ~ 2022-04-10: 99(days))
STUDY Teacher UPDATE_DATE INTERVAL_DAYS
math A 2022-02-25 0.55 (* 55/99, '55' is the period from 2022-01-01 to 2022-02-25)
math A, C 2022-02-25 0.44 (* 45/99)
science D 2022-01-03 0.02 (* 2/99)
science D, B 2022-01-03 0.98 (* 97/99)
entertainment C 2022-01-01 0.6 (* 60/99)
entertainment B, C 2022-03-02 0.4 (* 39/99)
technology E 2021-09-01 1
The blueprint is drawn in my head, but I am having a hard time writing code in python. It seemed like it would be a simpler solution than I thought, but I haven't been able to solve this problem for a long time. Please help.
CodePudding user response:
Use:
t = df['STUDY'].value_counts()
us = t[t==1].index.values
df.loc[(df['UPDATE_DATE'] >= from_date) & (df['UPDATE_DATE'] <= to_date)|(df['STUDY'].isin(us))]
Demonstration:
string = """ind STUDY Teacher UPDATE_DATE
0 math None -> A 2021-05-12
1 math A -> A, B 2021-09-23
2 math A, B -> A 2021-10-12
3 math A -> A, C 2022-02-25
4 science None -> A 2021-07-01
5 science A -> D 2021-09-09
6 science D -> D, B 2022-01-03
7 entertainment None -> C 2022-01-01
8 entertainment C -> B, C 2022-03-02
9 technology None -> E 2021-09-01"""
data = [x.split(' ') for x in string.split('\n')]
df = pd.DataFrame(data[1:], columns = data[0])
#soulution
from_date = '2022-01-01'
to_date = '2022-04-10'
df['UPDATE_DATE']=pd.to_datetime(df['UPDATE_DATE'])
t = df['STUDY'].value_counts()
us = t[t==1].index.values
df = df.loc[(df['UPDATE_DATE'] >= from_date) & (df['UPDATE_DATE'] <= to_date)|(df['STUDY'].isin(us))]
Output: