I have a common aggregation query:
SELECT
products.type,
count(products.id)
FROM
products
INNER JOIN product_colors
ON products.id = product_colors.product_id
AND product_colors.is_active = 1
AND product_colors.is_archive = 0
WHERE
(products.is_active = 1
AND product_colors.is_individual = 0
AND product_colors.is_visible = 1)
GROUP BY
type
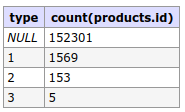
It lasts in the order of 0.1 seconds. The indexes look fine, tmp_table_size = 128M and max_heap_table_size = 128M. Why they are so slow? Classic selects are fast, but as there is group and count, no.
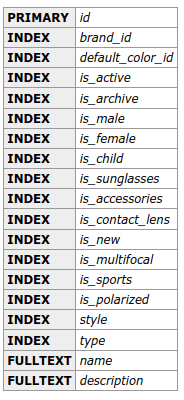
Indexes on products table:
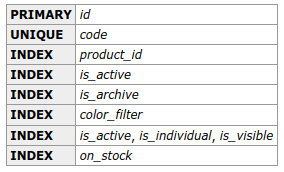
Indexes on product_colors table:
Explain SQL:

CodePudding user response:
Your indexing is not optimal for what you are asking. Instead of just having an index on each column individually (can be a big waste), you should have composite indexes that better match what you are trying to query and be covering enough to handle any group by or orderings.
In this case, you primary query is ACTIVE products and ordering by type. So I would have a SINGLE index on your primary table on (is_active, type, id). This way, your WHERE criteria is up front via Is_Active, then your order by via Type and finally the ID that qualifies the record. In this case, your query can get all it needs from the INDEX and not have to go to the raw data pages.
Now, your secondary table. Similarly should be composite index. First based on the criteria of the join between tables, THEN based on its restrictions you are looking for, thus: ( product_id, is_active, is_archive ). Why you have two columns of Is_Active and another for Is_Archive, dont know. I would think that if something were in the archives, it would not be active to begin with, but just a guess on that.
Anyhow, with the optimized indexes should help.
One last consideration on your count(product.id). Do you intend DISTINCT Products, or all records found. So if a one product has 8 colors, do you want the ID counted as 1 or 8.
count(*) would give 8
count( distinct product.id ) would give 1
CodePudding user response:
Give these a try:
products: INDEX(is_active, type)
product_colors: INDEX(product_id, is_individual, is_visible, is_active, is_archive)
Since products.id cannot be NULL, you may as well say COUNT(*) instead of count(products.id). (Or, as DRapp points out, maybe you need COUNT(DISTINCT products.id)