This is dataset with my variables for analysis.
clys<-structure(list(session_price = c(18824.7664, 35584.4106, 21084.4035,
9907.5856, 30806.5486, 15788.1279, 10147.7593, 11977.5904, 11734.3553,
53484.8698, 27788.9949, 11072.0588, 29241.0885, 5676.2372, 14007.0981,
34964.85, 14668.6735, 9425.9294, 16577.845, 153147.2272), flight_type = c(1.2462,
1.1691, 1.0601, 1.2909, 1.5488, 1.1279, 1.166, 1.3862, 1.2936,
1.0195, 1.0451, 1.2904, 1.6684, 1.2786, 1.1358, 1.2958, 1.05,
1.1522, 1.0561, 1.6795), adults_count = c(1.1793, 1.0821, 1.1156,
1.2565, 1.2742, 1.2283, 1.3237, 1.1494, 1.2904, 1.3525, 1.0814,
1.3644, 1.5781, 1.1816, 1.2604, 1.1732, 1.4088, 1.3959, 1.0959,
1.4726), children_count = c(0.2432, 0.0338, 0.1573, 0.0517, 0.0769,
0.0365, 0.1494, 0.0408, 0.1177, 0.128, 0.0579, 0.2749, 0.4045,
0.0823, 0.0943, 0.0677, 0.2088, 0.3009, 0.0817, 0.2353), infants_count = c(0.0152,
0.0048, 0.0731, 0.0259, 0.0129, 0.0046, 0.0954, 0.014, 0.0141,
0.0152, 0.0121, 0.0667, 0.0365, 0.0174, 0.0679, 0.0111, 0.0441,
0.0818, 0.0313, 0.0446), meta_flight_type = c(0.2918, 0.4686,
0.1425, 0.43, 0.3924, 0.6575, 0.6349, 0.0583, 0.2747, 0.167,
0.6179, 0.22, 0.5573, 0.2165, 0.3623, 0.6272, 0.3853, 0.1468,
0.255, 0.4604), flight_kind = c(0.4528, 0.1379, 3.6497, 0.2331,
0.3969, 0.1519, 0.098, NA, 0.6111, NA, 0.1086, 0.1061, NA, NA,
0.8571, 1.3472, NA, 0.0243, 3.3273, 1.1279), service_class_id = c(2,
1.9952, 2, 2, 1.9986, 2, 2, 1.9977, 2, 1.9913, 1.9968, 1.9985,
1.9983, 2, 2, 1.9994, 2, 1.9979, 1.9986, 1.9939), UI_profit = c(249.9766,
210.7159, 121.1932, 46.7757, 202.5403, 58.3467, 35.375, 0, 63.4536,
0, 116.4613, 41.2356, 0, 0, 72.0427, 131.8692, 0, 24.3831, 75.1906,
53), leg_price = c(9807.4805, 23253.6651, 15805.3328, 6148.6305,
15574.0215, 11339.653, 5964.4419, 7846.2151, 6910.2812, 35607.4389,
23953.2572, 5411.9416, 9544.5809, 3568.1491, 9463.4491, 23276.3196,
8357.9574, 4977.6056, 13331.1196, 54673.0944), flight_duration_min = c(307.2136,
269.9225, 439.2894, 143.2841, 197.8477, 110.2875, 114.3542, NA,
173.47, NA, 236.4197, 160.9437, NA, NA, 216.9208, 624.4288, NA,
162.4991, 190.5408, 776.6839), trip_duration_min = c(504.257,
531.7625, 967.9167, 261.4497, 265.9794, 138.0625, 163.9792, NA,
325.6778, NA, 459.6784, 166.7464, NA, NA, 462.5097, 949.2419,
NA, 162.6241, 478.7249, 1346.6982), price_duration_min = c(27.8457,
78.404, 35.9824, 38.95, 56.0142, 102.8833, 49.24, NA, 33.841,
NA, 96.4814, 29.3607, NA, NA, 43.4476, 33.1768, NA, 28.893, 76.8556,
45.4329), days_to_flight = c(27.8068, 23.0823, 23.7821, 12.4188,
26.8415, 19.6586, 24.6713, 16.6704, 13.9125, 10.1796, 13.2141,
18.1858, 119.3786, 12.5782, 20.3807, 31.856, 37.4516, 6.9034,
21.6605, 43.7275), days_RT = c(12.8218, 8.904, 23.2507, 4.585,
8.5987, 13.0174, 7.6805, 6.4065, 4.219, 19.984, 11.874, 8.8732,
14.4032, 4.9503, 11.9996, 12.5172, 4.9677, 8.0309, 12.8996, 15.5516
), mobile_share = c(0.538, 0.5845, 0.7576, 0.5409, 0.5279, 0.6119,
0.6017, 0.5344, 0.5133, 0.7007, 0.7336, 0.7531, 0.5156, 0.6429,
0.7208, 0.6033, 0.7118, 0.8446, 0.6328, 0.6268), desktop_share = c(0.4559,
0.4155, 0.2424, 0.3556, 0.4687, 0.3881, 0.3983, 0.4656, 0.4757,
0.2993, 0.2626, 0.2382, 0.4844, 0.3571, 0.2792, 0.3924, 0.2882,
0.1519, 0.3643, 0.3732), iphone_share = c(0.2128, 0.2947, 0.1443,
0.3103, 0.3459, 0.3379, 0.1618, 0.2882, 0.2308, 0.4707, 0.2606,
0.4327, 0.1892, 0.277, 0.2453, 0.2805, 0.1853, 0.478, 0.1882,
0.3834), android_share = c(0.307, 0.2657, 0.6087, 0.2274, 0.1697,
0.2694, 0.4274, 0.2322, 0.2779, 0.2115, 0.4685, 0.3165, 0.3177,
0.361, 0.4755, 0.3196, 0.5176, 0.3668, 0.4432, 0.2414), multi_share = c(0.2888,
0.0676, 0.8825, 0.1078, 0.0807, 0.0365, 0.1411, 0.0292, 0.2229,
0.0412, 0.1354, 0.1619, 0.0972, 0.1538, 0.1585, 0.3809, 0.1324,
0.0902, 0.473, 0.211), CR_session_to_popup = c(0.1185, 0.1159,
0.0879, 0.2295, 0.1276, 0.2374, 0.1162, 0.1097, 0.1695, 0.1605,
0.1062, 0.2189, 0.0226, 0.2356, 0.166, 0.1383, 0.1118, 0.2994,
0.0874, 0.0467), CR_session_to_booking = c(0.1155, 0.1063, 0.0703,
0.2392, 0.1208, 0.2237, 0.1079, 0.1995, 0.1648, 0.1844, 0.082,
0.1826, 0.0313, 0.2339, 0.1472, 0.1141, 0.1118, 0.2515, 0.0739,
0.0548), corr_winter = c(0.2635, 0.1983, 0.2513, 0.1867, 0.106,
0.4188, 0.0534, 0.1589, 0.2498, 0.4775, 0.4858, 0.3605, 0.0688,
0.318, 0.3394, 0.223, 0.3281, 0.3985, 0.173, 0.112), corr_spring = c(0.3036,
0.2772, 0.2602, 0.2209, 0.3627, 0.1332, 0.4484, 0.2793, 0.2526,
0.506, 0.0814, 0.2088, 0.6824, 0.2407, 0.1407, 0.326, 0.3228,
0.0654, 0.0897, 0.3196), corr_summer = c(0.2673, 0.1791, 0.258,
0.2894, 0.2856, 0.099, 0.2358, 0.2793, 0.276, 0.0165, 0.2525,
0.2087, 0.2488, 0.4413, 0.2477, 0.2744, 0.3491, 0.2917, 0.5926,
0.0861), corr_autumn = c(0.1656, 0.3454, 0.2304, 0.3029, 0.2458,
0.349, 0.2625, 0.2826, 0.2216, 0, 0.1803, 0.222, 0, 0, 0.2722,
0.1766, 0, 0.2444, 0.1447, 0.4823), corr_BL = c(0.4759, 0.5444,
0.4952, 0.4392, 0.4586, 0.4146, 0.4011, 0.4722, 0.4244, 0.4542,
0.4742, 0.4467, 0.4652, 0.4293, 0.4412, 0.4423, 0.4811, 0.4583,
0.496, 0.4882), corr_UP = c(0.5241, 0.4556, 0.5048, 0.5608, 0.5414,
0.5854, 0.5989, 0.5278, 0.5756, 0.5458, 0.5258, 0.5533, 0.5348,
0.5707, 0.5588, 0.5577, 0.5189, 0.5417, 0.504, 0.5118), pam_german.clustering = c(1L,
2L, 2L, 3L, 4L, 4L, 5L, 6L, 1L, 7L, 7L, 8L, 6L, 9L, 8L, 9L, 9L,
8L, 2L, 2L)), class = "data.frame", row.names = c(NA, -20L))
pam_german.clustering is the number of the cluster in which the observation is belong (row)
How for all variable from session_price to corr_UP between all clusters to draw a histogram of the distribution of variables?
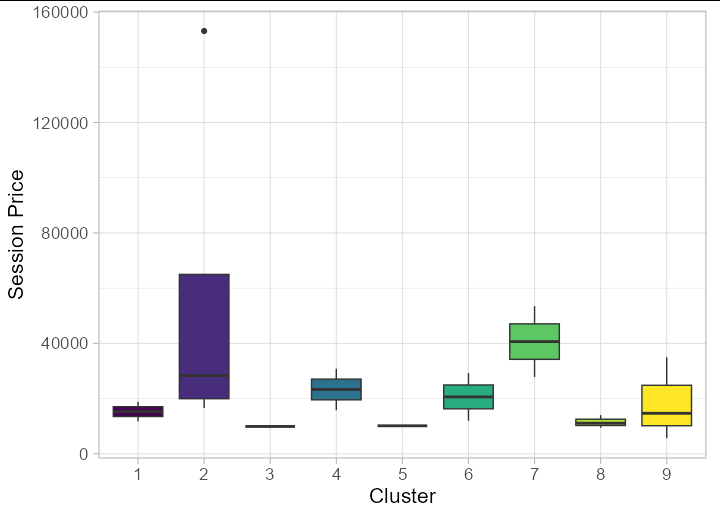
I only learn ggplot2, so can't do it self. But to explain what result i need , i can draw using paint.
For session price histogram between cluster
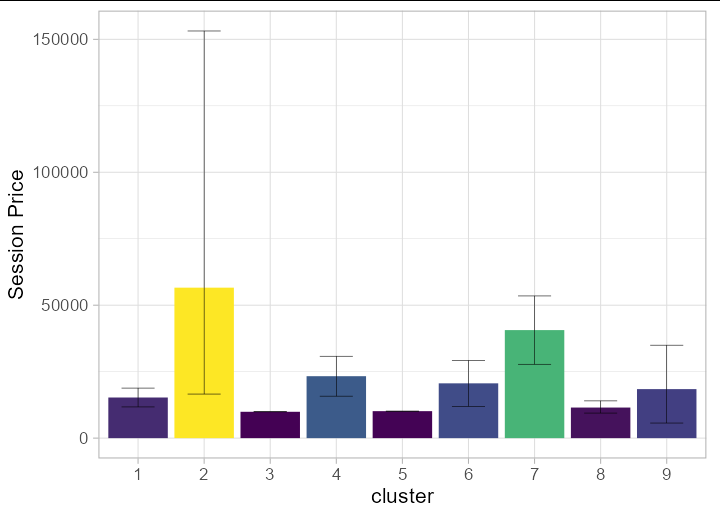
Or perhaps you are wanting columns of averages per cluster with an error bar representing the range?
library(tidyverse)
clys %>%
group_by(pam_german.clustering) %>%
summarize(max = max(session_price),
min = min(session_price),
session_price = mean(session_price),
cluster = factor(mean(pam_german.clustering))) %>%
ggplot(aes(x = cluster, y = session_price, fill = session_price))
geom_col()
geom_errorbar(aes(ymin = min, ymax = max), width = 0.5, size = 0.2)
scale_fill_viridis_c(option = 7)
theme_light(base_size = 16)
labs(y = 'Session Price')
guides(fill = guide_none())
Certainly, a set of histograms is possible, but really doesn't work very well with this data set due to the lack of data points, and trying to fit too many facets across a single dimension of the plot:
clys %>%
ggplot(aes(x = session_price))
geom_histogram()
facet_grid(.~pam_german.clustering, scales = 'free_x')
theme_light(base_size = 16)