So this may seem like a simple question, but every question I've checked isn't exactly approaching the problem in the same way I am.
I'm trying to bin the timestamps of a dataframe into specific buckets. I want to be able to count every minute of a dataframe starting from the first row until the last. I then want to turn that counted minute into a bucket (starting from 1 going to n). I then want to count every row what second it was for the timestamp of that row until the end of the bin.
Here is an example of what I want it to look like:
| time_bin | seconds_in_bin | time |
|---|---|---|
| 1 | 1 | 2022-05-05 22:12:59 |
| 1 | 2 | 2022-05-05 22:13:00 |
| 1 | 3 | 2022-05-05 22:13:01 |
| 1 | 4 | 2022-05-05 22:13:02 |
I'm currently working in python and am trying to do this in pandas with my data. I feel like this problem is much easier than I think it is and I'm just not thinking of the right solution, but some help would be appreciated.
CodePudding user response:
I am not sure I quite get what you are going for here but wouldn't this be equivalent to getting the rank of seconds?
As far as I understand it, binning has to do with putting together an interval (fixed or not) and counting the number of items in it. If you could please elaborate on this I'll do my best to help with a more plausible answer.
CodePudding user response:
Use:
string = '''2022-05-05 22:12:59
2022-05-05 22:13:00
2022-05-05 22:13:01
2022-05-05 22:13:02
2022-05-05 22:14:59'''
df = pd.DataFrame({'time': string.split('\n')})
df['s'] = pd.to_datetime(df['time']).dt.second
df['m'] = pd.to_datetime(df['time']).dt.minute
df['g'] = (df['s'].diff() df['m'].diff()*60).fillna(method='bfill').diff().clip(upper=1).fillna(method='bfill') 1
df['count'] = df.groupby('g')['g'].cumsum()/df['g']
df
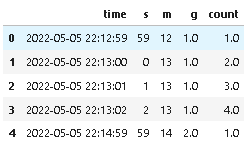
Output: