I have csv file about 3GB large I want to read it with dask. and I want to perform an operation on this data which is to select some columns which contain a specific data.
For example:
I want to get all the ids which are in df
ids = ['SW00003062', 'SW00003063', 'SW00003067', 'SW00003072']
from this dask dataframe:
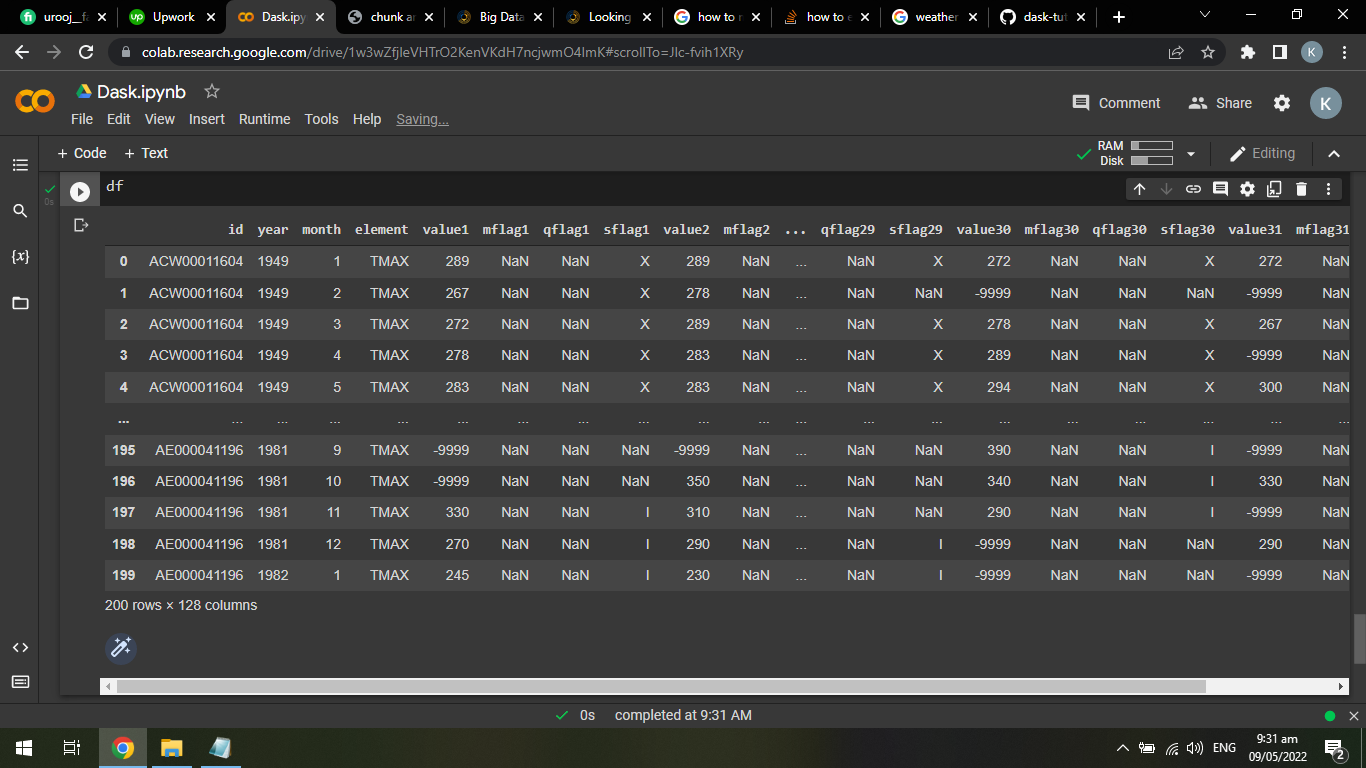
Simply get the dataframe which contains the id of ids list
CodePudding user response:
what about this
import pandas
random_name = pandas.read_csv("insert file name")
random_name["column title"] #this should give you your column of choice
list = random name["column title"].to_list() #turns column to list
CodePudding user response:
Dask has very similar syntax to pandas, that means, most of the pandas command are supported. For your requirement you can do the following:
df = pd.DataFrame(
{
'size': random.random(size=100),
'label': random.choice(['a', 'b', 'c'], size=100, replace=True)
}
)
dask_df = dd.from_pandas(df, npartitions=2)
# to get the unique values from a column
dask_df.label.unique().compute()
# to index a column based on condition
dask_df.loc[dask_df.label == 'a', :].compute()
Note that, dask stores an operation as a task, to actually execute those tasks one has to call the compute() function on expressions.