I'm trying to create a consolidated report from another report. The initial data I have is in this format
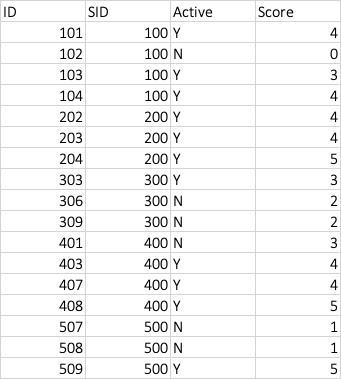
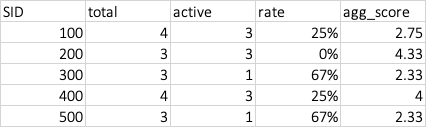
The final report collapses basis supervisor ID and keeps a track of the count of directs and scores, which looks like:
What I've tried is quite lengthy and tedious and if there are a lot more parameters to capture, it requires quite a bit of time and increases the number of lines of code significantly. I'm seeking a smarter way of creating this report, involving less lines of code and may sacrifice on readability such as comprehension methods. Any help is well appreciated.
My code below:
xdf = pd.DataFrame({'ID':[101,102,103,104,202,203,204,303,306,309,401,403,407,408,507,508,509],
'SID':[100,100,100,100,200,200,200,300,300,300,400,400,400,400,500,500,500],
'Active':['Y','N','Y','Y','Y','Y','Y','Y','N','N','N','Y','Y','Y','N','N','Y'],
'Score':[4,0,3,4,4,4,5,3,2,2,3,4,4,5,1,1,5,]})
xdf['Active'] = np.where(xdf['Active']=='Y',1,0)
print(xdf)
xdf_tc = xdf.groupby('SID')['ID'].count().reset_index()
xdf_ac = xdf.groupby('SID')['Active'].sum().reset_index()
xdf_sc = xdf.groupby('SID')['Score'].mean().reset_index()
ydf = pd.merge(xdf_tc,xdf_ac,how='left',on='SID')
ydf = pd.merge(ydf,xdf_sc,how='left',on='SID')
ydf = ydf.rename(columns={'ID': 'total',
'Score':'agg_score'})
ydf['rate'] = round(1-(ydf['Active']/ydf['total']),2)
print(ydf)
CodePudding user response:
I think instead of grouping by in different operations and merging back to the original df, you could do it in one go, and then, add 'rate'. Something like:
tmp=xdf.groupby('SID').agg({'ID':'count','Active':'sum','Score':'mean'}).rename(columns={'ID': 'total','Score':'agg_score'})
tmp['rate'] = round(1-(tmp['Active']/tmp['total']),2)
tmp
CodePudding user response:
You can simplify your solution with named aggregation:
xdf['Active'] = np.where(xdf['Active']=='Y',1,0)
ydf = xdf.groupby('SID').agg(total=('ID','count'),
Active=('Active','sum'),
agg_score=('Score','mean'))
ydf['rate'] = round(1-(ydf['Active']/ydf['total']),2)
print(ydf)
total Active agg_score rate
SID
100 4 3 2.750000 0.25
200 3 3 4.333333 0.00
300 3 1 2.333333 0.67
400 4 3 4.000000 0.25
500 3 1 2.333333 0.67
Also is possible use:
ydf = (xdf.assign(Active = xdf['Active']=='Y')
.groupby('SID')
.agg(total=('ID','count'),
Active=('Active','sum'),
agg_score=('Score','mean')))
ydf['rate'] = round(1-(ydf['Active']/ydf['total']),2)
print(ydf)
total Active agg_score rate
SID
100 4 3 2.750000 0.25
200 3 3 4.333333 0.00
300 3 1 2.333333 0.67
400 4 3 4.000000 0.25
500 3 1 2.333333 0.67
CodePudding user response:
You can use named aggregation and if the order of the columns is important, use reindex at the end.
res = df.groupby('SID').agg(total=('SID','count'), Active=('Active', lambda x: (x=='Y').sum()), agg_score=('Score', 'mean'))
res['rate'] = [f"{1-x:.0%}" for x in res['Active']/res['total']]
res.reindex(columns=['total', 'Active','rate','agg_score'])
print(res)
total Active rate agg_score
SID
100 4 3 25% 2.750000
200 3 3 0% 4.333333
300 3 1 67% 2.333333
400 4 3 25% 4.000000
500 3 1 67% 2.333333