i was reading through the pandas documentation (10 minutes to pandas) and came across this example:
dates = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.randn(8, 4),
index=dates, columns=['A', 'B', 'C', 'D'])
s = df['A']
s[dates[5]]
# Out[5]: -0.6736897080883706
It's quite logic, but if I try it on my own and set the indexname afterwards (example follows), then i can't select data with s[dates[5]]. Does someone know why?
e.g.
df = pd.read_csv("xyz.csv").head(100)
s = df['price'] # series with unnamed int index price
s = s.rename_axis('indexName')
s[indexName[5]] # NameError: name 'indexName' is not defined
Thanks in advance!
Edit: s.index.name returns indexName, despite not working with the call of s[indexName[5]]
CodePudding user response:
You are confusing the name of the index, and the index values.
In your example, the first code chunk runs because dates is a variable, so when you call dates[5] it actually returns the 5th value from the dates object, which is a valid index value in the dataframe.
In your own attempt, you are referring to indexName inside your slice (ie. when you try to run s[indexName[5]]), but indexName is not a variable in your environment, so it will throw an error.
The correct way to subset parts of your series or dataframe, is to refer to the actual values of the index, not the name of the axis. For example, if you have a series as below:
s = pd.Series(range(5), index=list('abcde'))
Then the values in the index are a through e, therefore to subset that series, you could use:
s['b']
or:
s.loc['b']
Also note, if you prefer to access elements by location rather than index value, you can use the .iloc method. So to get the second element, you would use:
s.iloc[1] # locations 0 is the first element
Hope it helps to clarify. I would recommend you continue to work through some introductory pandas tutorials to build up a basic understanding.
CodePudding user response:
First of all lets understand the example:
df[index] is used to select a row having that index.
This is the s dataframe:
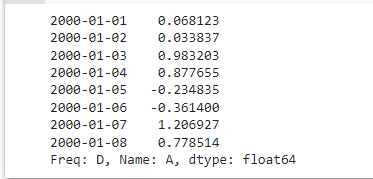
The indexes are the dates.
The dates[5] is equal to '2000-01-06'which is the index of the 5th row of the s df. so, the result is the row having that index.
in your code:
indexName is not defined. so, indexName[5] is not representing an index of your df.