I am trying to run some geospatial transformations in Delta Live Table, using Apache Sedona. I tried defining a minimal example pipeline demonstrating the problem I encounter.
First cell of my Notebook, I install apache-sedona Python package:
%pip install apache-sedona
then I only use SedonaRegistrator.registerAll (to enable geospatial processing in SQL) and return an empty dataframe (that code is not reached anyway):
import dlt
from pyspark.sql import SparkSession
from sedona.register import SedonaRegistrator
@dlt.table(comment="Test temporary table", temporary=True)
def my_temp_table():
SedonaRegistrator.registerAll(spark)
return spark.createDataFrame(data=[], schema=StructType([]))
I created the DLT Pipeline leaving everything as default, except for the spark configuration:
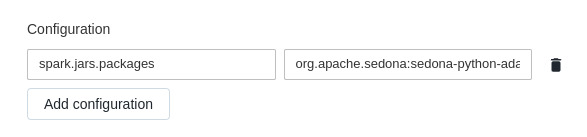
Here is the uncut value of spark.jars.packages: org.apache.sedona:sedona-python-adapter-3.0_2.12:1.2.0-incubating,org.datasyslab:geotools-wrapper:1.1.0-25.2.
This is required according to this