I have the following regex. I would like to extract all into seperate rows anything between ":".
I have highlighted in bold every other word to help make it easier to read the code but basically the pattern is
title column1: value1 title column2:value2 title column 3: value3
While the below patterns suggest the titles are reoccurring, please note that sometimes one of the fields values may be blank.
I appreciate any help if someone is able to extract separate the title column from title names into a table format
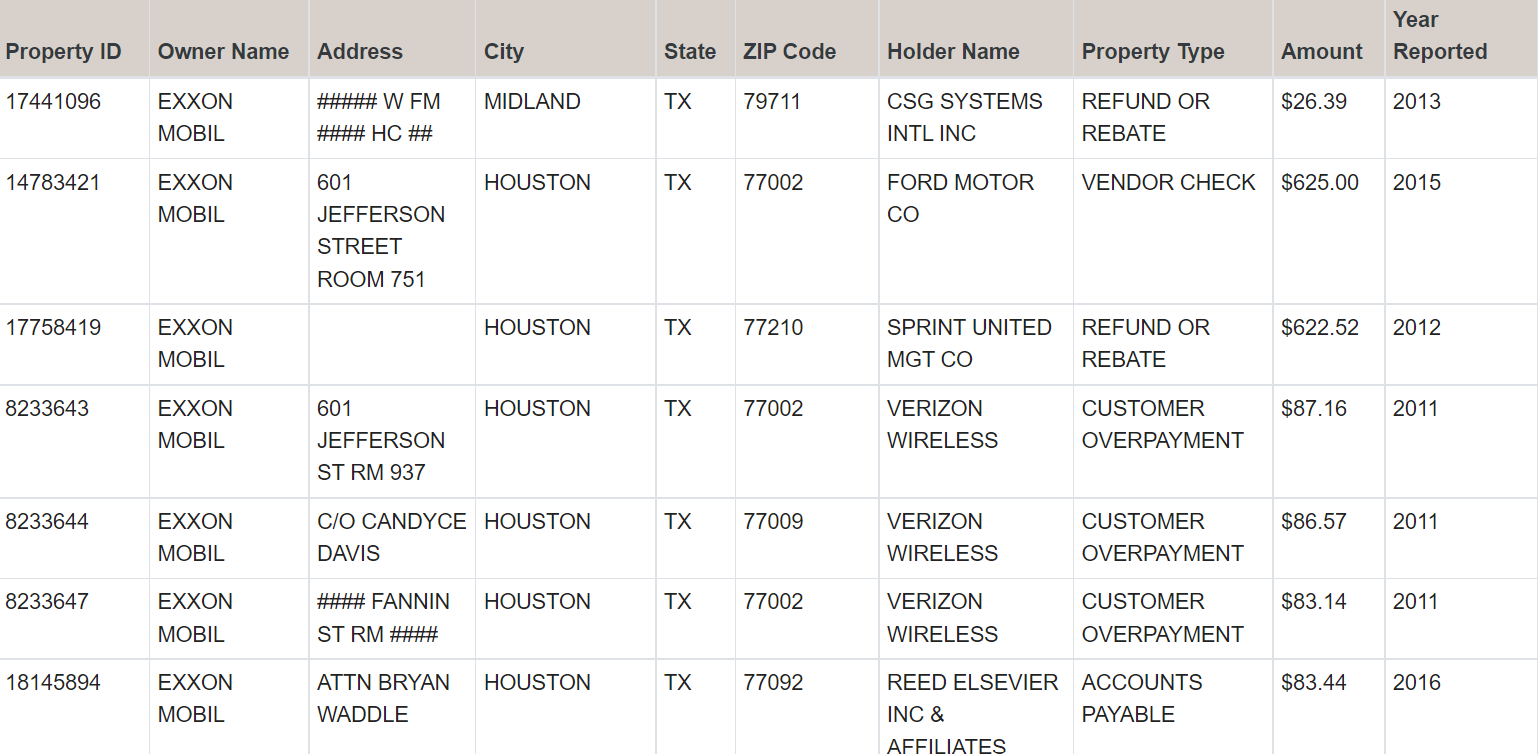
Example data is below
"CLAIMcloseRemoveProperty ID: 17441096 Owner Name: EXXON MOBIL Address: ##### W FM #### HC ## City: MIDLAND State: TX ZIP Code: 79711 Holder Name: CSG SYSTEMS INTL INC Property Type: REFUND OR REBATE Amount: $26.39 Year Reported: 2013 CLAIMcloseRemoveProperty ID: 14783421 Owner Name: EXXON MOBIL Address: 601 JEFFERSON STREET ROOM 751 City: HOUSTON State: TX ZIP Code: 77002 Holder Name: FORD MOTOR CO Property Type: VENDOR CHECK Amount: $625.00 Year Reported: 2015"
CodePudding user response:
The below works if you know the headings (i.e. they are 'hard coded').
## read in the sample data
sampleData = c("CLAIMcloseRemoveProperty ID: 17441096 Owner Name: EXXON MOBIL Address: ##### W FM #### HC ## City: MIDLAND State: TX ZIP Code: 79711 Holder Name: CSG SYSTEMS INTL INC Property Type: REFUND OR REBATE Amount: $26.39 Year Reported: 2013 CLAIMcloseRemoveProperty ID: 14783421 Owner Name: EXXON MOBIL Address: 601 JEFFERSON STREET ROOM 751 City: HOUSTON State: TX ZIP Code: 77002 Holder Name: FORD MOTOR CO Property Type: VENDOR CHECK Amount: $625.00 Year Reported: 2015")
## Set up known values
headings = c("CLAIMcloseRemoveProperty ID", "Owner Name", "Address", "City", "State", "ZIP Code", "Holder Name", "Property Type", "Amount", "Year Reported")
## replace all headers with the same quantity
newData = gsub(paste(paste0(headings, ":"), collapse="|"), "XXHEADINGXX:", sampleData)
## Remove the known values
values = unlist(strsplit(newData, "XXHEADINGXX:"))[-1]
## Extract the data
data = matrix(values, length(headings), length(values)/length(headings))
## Turn into a data frame with headings as above
data = as.data.frame(t(data))
names(data) = headings
CodePudding user response:
You could use read.dcf as follows:
fields <- c("CLAIMcloseRemoveProperty ID", "Owner Name", "Address",
"City", "State", "ZIP Code", "Holder Name",
"Property Type", "Amount", "Year Reported")
text <- gsub(sprintf('(%s)', paste0(fields, collapse = '|')),'\n\\1', string)
text1 <- gsub("(CLAIMcloseRemoveProperty ID)", "\n\\1", text)
read.dcf(textConnection(text1), all = TRUE)
I added an extra line break for every new row. That is just to ensure the data is in a valid dcf format. You do not need it if there is only one row as in your case