I have created a pivot table where the column headers have several levels. This is a simplified version:
index = ['Person 1', 'Person 2', 'Person 3']
columns = [
["condition 1", "condition 1", "condition 1", "condition 2", "condition 2", "condition 2"],
["Mean", "SD", "n", "Mean", "SD", "n"],
]
data = [
[100, 10, 3, 200, 12, 5],
[500, 20, 4, 750, 6, 6],
[1000, 30, 5, None, None, None],
]
df = pd.DataFrame(data, columns=columns)
df
Now I would like to highlight the adjacent cells next to SD if SD > 10. This is how it should look like:
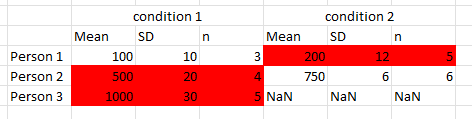
I found this answer but couldn't make it work for multiindices.
Thanks for any help.
CodePudding user response:
Use Styler.apply with custom function - for select column use DataFrame.xs and for repeat boolean use DataFrame.reindex:
def hightlight(x):
c1 = 'background-color: red'
mask = x.xs('SD', axis=1, level=1).gt(10)
#DataFrame with same index and columns names as original filled empty strings
df1 = pd.DataFrame('', index=x.index, columns=x.columns)
#modify values of df1 column by boolean mask
return df1.mask(mask.reindex(x.columns, level=0, axis=1), c1)
df.style.apply(hightlight, axis=None)