I have two dataframes like as below
row_id,var_name,score
1,revenue,10
1,cnt_days,5
1,age,15
2,revenue,11
2,cnt_days,3
2,age,25
df1 = pd.read_clipboard(sep=',')
unique_key,status,country,marital_status
123,passed,UK,Single
456,failed,USA,Married
789,passed,KOREA,Single
df2 = pd.read_clipboard(sep=',')
I would like to do the below
a) Match df1 and df2 based on df1['row_id'] and df2.index
b) For matching records, attach unique_key to df1
So, I tried the below
pd.concat([df1, df2[['unique_key']].reset_index(drop=True)], axis=1)
but the above doesn't work for repeating row_ids. It only matches for first occurrence of row_ids.
How can I do this for repeat occurrence of row_ids in big data dataframe?
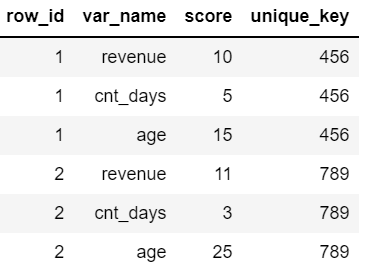
I expect my output to be like as below
CodePudding user response:
Because match by indices in df2 is possible use Series.map by Series - df2['unique_key']:
df1['unique_key'] = df1['row_id'].map(df2['unique_key'])
print (df1)
row_id var_name score unique_key
0 1 revenue 10 456
1 1 cnt_days 5 456
2 1 age 15 456
3 2 revenue 11 789
4 2 cnt_days 3 789
5 2 age 25 789
Or left join with only column unique_key with parameters left_on and right_index:
df = df1.merge(df2['unique_key'], left_on='row_id', right_index=True, how='left')
print (df)
row_id var_name score unique_key
0 1 revenue 10 456
1 1 cnt_days 5 456
2 1 age 15 456
3 2 revenue 11 789
4 2 cnt_days 3 789
5 2 age 25 789
CodePudding user response:
df1['unique_key'] = df1.merge(df2, right_index=True, left_on='row_id')['unique_key']
print(df1)
row_id var_name score unique_key
0 1 revenue 10 456
1 1 cnt_days 5 456
2 1 age 15 456
3 2 revenue 11 789
4 2 cnt_days 3 789
5 2 age 25 789