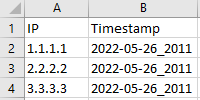
I have a job which runs every 15 mins and returns an IP array list like this
listofIPs = ['1.1.1.1', '2.2.2.2', '3.3.3.3']
I maintain this in a masterlist.csv file against the date like this.
IP,Timestamp
1.1.1.1,2022-05-12_2030
2.2.2.2,2022-05-12_2030
3.3.3.3,2022-05-12_2030
5.5.5.5,2022-05-12_1430
8.8.8.8,2022-05-11_1930
1.1.1.1,2022-05-06_2030
Every 15 mins the job returns some IP list.We need to check if any IP from the list is NOT present in master csv in last 24 hours and then only append that IP to master csv file
I want to achieve this using Pandas dataframes or basic python,and not Pyspark etc
I have tried something like this but it didn't work
mainfile = '/Users/Documents/masterlist.csv'
runtime = datetime.strftime(now , '%Y-%m-%d_%H%M')
listofIPs = ['1.1.1.1', '2.2.2.2', '3.3.3.3']
dateparse = lambda x: datetime.strptime(x, '%Y-%m-%d_%H%M')
df = pd.read_csv(mainfile, parse_dates=['Timestamp'], date_parser=dateparse)
recent_df = df[df.timestamp > datetime.now() - pd.to_timedelta("1day")]
badip_df = recent_df.drop_duplicates("IP", keep='last')
if badip_df.empty:
badip_df['Timestamp'] = runtime
badip_df = badip_df[[listofIPs, 'Timestamp']]
badip_df.to_csv(mainfile, index=False)
else:
badip_df.to_csv(mainfile, mode='a', index=False, header=False)
Can someone please help?
CodePudding user response:
datetime.strftime, datetime.strptime, and datetime.now() don't exist. All of those are methods of datetime.datetime, e.g. datetime.datetime.now() [EDIT: oh, unless you imported using from datetime import datetime].
Also, as mentioned in the comments, goodfp_df is not defined before it is first used. Fix those problems, and you'll be somewhere. Is it supposed to be defined as recent_df[~recentdf.duplicated(keep=False)], by any chance?
Also, df.timestamp should be df.Timestamp, and now isn't defined (should be datetime.now()).
Finally, listofIPs is a list and thus can't be a column title of a dataframe.
CodePudding user response:
Is this what you're looking for? I'm using the masterlist.csv described above as a starting point.
import pandas as pd
from datetime import datetime
mainfile = 'masterlist.csv'
runtime = datetime.strftime(datetime.now() , '%Y-%m-%d_%H%M')
listofIPs = ['1.1.1.1', '2.2.2.2', '3.3.3.3']
dateparse = lambda x: datetime.strptime(x, '%Y-%m-%d_%H%M')
df = pd.read_csv(mainfile, parse_dates=['Timestamp'], date_parser=dateparse)
recent_df = df[df.Timestamp > datetime.now() - pd.to_timedelta("30day")] #30day to get all
badip_df = recent_df.drop_duplicates("IP", keep='last')
if badip_df.empty:
badip_df = pd.DataFrame(listofIPs, columns=['IP'])
badip_df['Timestamp'] = runtime
badip_df.to_csv(mainfile, index=False)
else:
badip_df.to_csv(mainfile, mode='a', index=False, header=False)
When pd.to_timedelta() is set as "30day", the output is
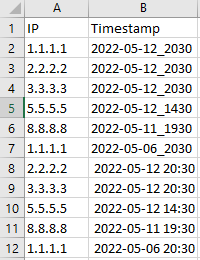
When pd.to_timedelta() is set as "5day", the output is