I have a 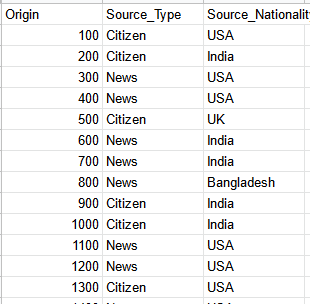
What I want to do is to find how the normalized value (via value_counts(normalize = True)*100) of the top 3 nationality per source_type
So, it should look like:

So far I have tried this:
df.groupby(['Source_Type'])['Source_Nationality'].value_counts(normalize=True)*100
But the above code is giving the WHOLE dataset (see below)
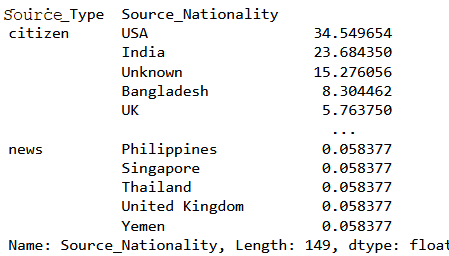
So I tried adding .head(3). This one only shows the top 3 of the citizen and not the news part.
(df.groupby(['Source_Type'])['Source_Nationality'].value_counts(normalize = True)*100).head(3)

CodePudding user response:
In your case try head
out = df.groupby(['Source_Type'])['Source_Nationality'].value_counts(normalize=True)*100
out = out.sort_values(ascending=False).groupby(level=0).head(3)
CodePudding user response:
You need to apply head to each of the groups. Try:
>>> df.groupby("Source_Type")["Source_Nationality"].apply(lambda x: x.value_counts(normalize=True).mul(100).head(3))