I have the following code:
split_melt_and_transform_this_df = {'Concat' : [('AA,ABC,1,10,|','BB,ABC,,1,Z|','BB,ABC,,1,Z|''CC,ABC,50,,Z|'),('AA,ABC,1,10,|','BB,ABC,1,,Z|'),('AA,ABC,1,10,|','BB,ABC,1,,Z|'),('AA,ABC,5,,z|')], 'Item' : ['Backstreet Boys','NYSYNC', 'One Direction', 'Nirvana']}
split_melt_and_transform_this_df = pd.DataFrame(split_this_df)
split_melt_and_transform_this_df
I'd like to transform this 'Current DF' into the following 'Desired DF1' and 'Desired DF2' data frames:
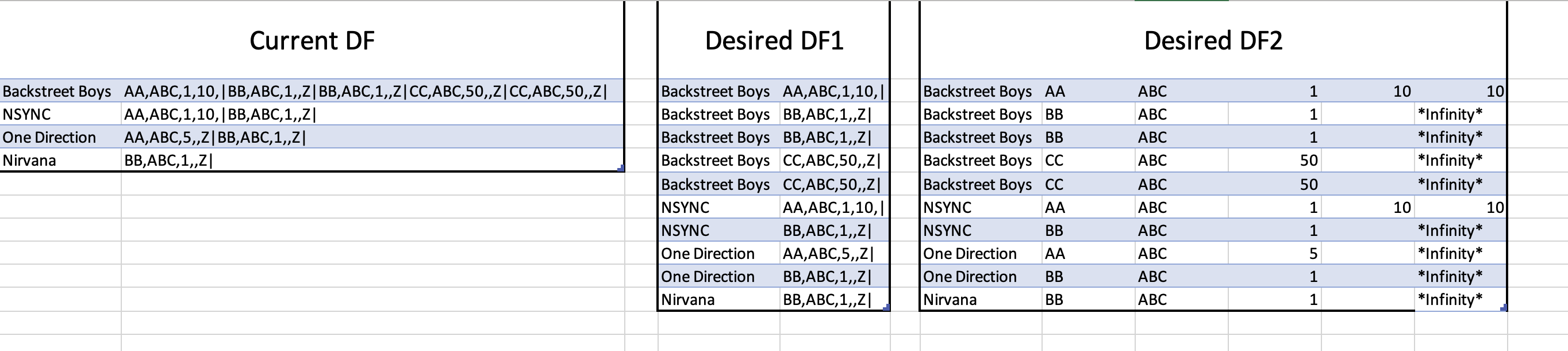
DF2 is the especially tricky part. All 'Z' values that end up in the final column need to be infinity. If the row in the final column is blank, then show the value in the row of the adjacent column (i.e., second to last column, where the '10' value shows).
CodePudding user response:
You can try explode to get df1
df1 = df.explode('Concat', ignore_index=True)
print(df1)
Concat Item
0 AA,ABC,1,10,| Backstreet Boys
1 BB,ABC,,1,Z| Backstreet Boys
2 BB,ABC,,1,Z| Backstreet Boys
3 CC,ABC,50,,Z| Backstreet Boys
4 AA,ABC,1,10,| NYSYNC
5 BB,ABC,1,,Z| NYSYNC
6 AA,ABC,1,10,| One Direction
7 BB,ABC,1,,Z| One Direction
8 AA,ABC,5,,Z| Nirvana
To get df2, you can try to split the Concat column and convert list column to dataframe.
df2 = df1.join(pd.DataFrame(df1.pop('Concat').str.split(',').tolist(), index=df1.index))
df2[4] = np.select([df2[4].eq('|'), df2[4].eq('Z|')], [df2[3], np.inf])
print(df2)
Item 0 1 2 3 4
0 Backstreet Boys AA ABC 1 10 10
1 Backstreet Boys BB ABC 1 inf
2 Backstreet Boys BB ABC 1 inf
3 Backstreet Boys CC ABC 50 inf
4 NYSYNC AA ABC 1 10 10
5 NYSYNC BB ABC 1 inf
6 One Direction AA ABC 1 10 10
7 One Direction BB ABC 1 inf
8 Nirvana AA ABC 5 inf