I have a dataframe like this:
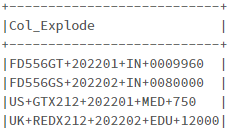
The first 2 records have 4 columns ( is the delimiter) and last 2 records have 5 columns.
How to move these records into 2 dataframes?
CodePudding user response:
You can do it using regex (rlike)
from pyspark.sql import functions as F
df = spark.createDataFrame([('q w e r',), ('q w e r t',)], ['Col_Explode'])
df2 = df.filter(F.col('Col_Explode').rlike(r'^([^ ] \ ){3}[^ ] $'))
df3 = df.filter(F.col('Col_Explode').rlike(r'^([^ ] \ ){4}[^ ] $'))
df.show()
# -----------
# |Col_Explode|
# -----------
# | q w e r|
# | q w e r t|
# -----------
df2.show()
# -----------
# |Col_Explode|
# -----------
# | q w e r|
# -----------
df3.show()
# -----------
# |Col_Explode|
# -----------
# | q w e r t|
# -----------
CodePudding user response:
Perhaps you can split() the content, and filter based on the size() of the result:
>>> df.show()
-----------------------
|Col_Explode |
-----------------------
|one two three four |
|one two three four five|
-----------------------
>>> for i in range(1,10):
... print('DF with ' str(i) ' columns')
... df.where(size(split('Col_Explode','\\ ')) == i).show()
...
DF with 1 columns
-----------
|Col_Explode|
-----------
-----------
:
:
DF with 4 columns
------------------
|Col_Explode |
------------------
|one two three four|
------------------
DF with 5 columns
-----------------------
|Col_Explode |
-----------------------
|one two three four five|
-----------------------
:
: