I am creating a timeregistry in SQL and almost have created the desired view.
What I need is a view with 1 row per date employee and the first and last recorded activity of that day. I use DATEFROMPARTS first to extract the date. I have used the "group by" statement to filter out duplicate date employee combinations. unfortunately, this only works with 2 existing columns and thus not the created date-column. I have added a table in 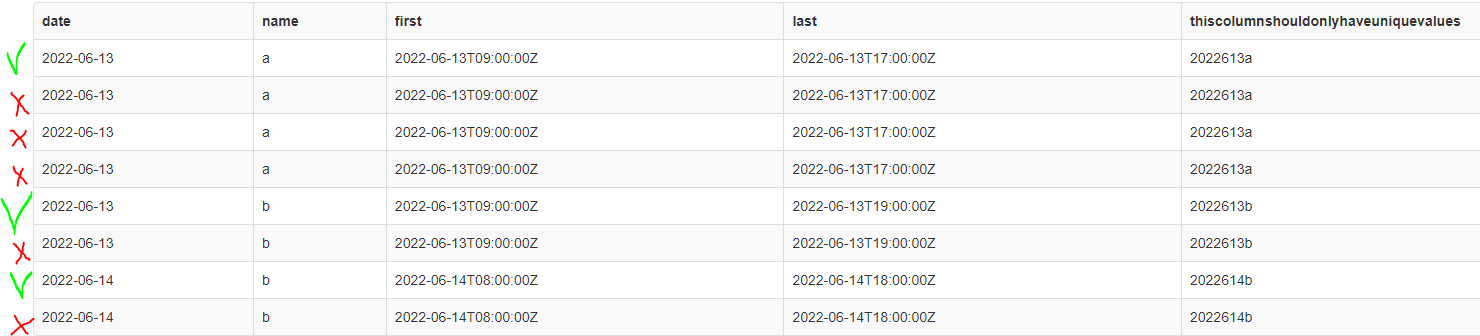
CodePudding user response:
The solution for your problem is that you need to use DISTINCT.
select distinct
DATEFROMPARTS(year(dt), month(dt), day(dt)) as date,
name,
min(dt) over(partition by Datepart(dy, dt), name) as first,
max(dt) over(partition by Datepart(dy, dt), name) as last,
concat(year(dt), month(dt), day(dt), name) as thiscolumnshouldonlyhaveuniquevalues
from employees
where name <> 'noname'
group by dt, name having count(concat(year(dt), month(dt), day(dt), name))= 1
order by date asc, name asc
CodePudding user response:
You need to make few changes in your query like -
- Use aggregate function instead of Window function.
- Get rid of Having clause.
- I have updated the GROUP BY clause also.
SELECT DATEFROMPARTS(YEAR(dt), MONTH(dt), DAY(dt)) AS date,
name,
MIN(dt) AS first,
MAX(dt) AS last,
CONCAT(YEAR(dt), MONTH(dt), DAY(dt), name) as thiscolumnshouldonlyhaveuniquevalues
FROM employees
WHERE name <> 'noname'
GROUP BY YEAR(dt), MONTH(dt), DAY(dt), name
ORDER BY date asc, name asc;
CodePudding user response:
Bogner Roys tip and Ankits Bajpai's answers made me rethink the group by clause, and the following (added distinct, removed group by) seems to do exactly as I desire.
select distinct
DATEFROMPARTS(year(dt), month(dt), day(dt)) as date,
name,
min(dt) over(partition by Datepart(dy, dt), name) as first,
max(dt) over(partition by Datepart(dy, dt), name) as last,
concat(year(dt), month(dt), day(dt), name) as thiscolumnshouldonlyhaveuniquevalues
from employees
where name <> 'noname'
order by date asc, name asc
CodePudding user response:
All you need is keyword distinct. Group by is used when you have to apply aggregate operators to each group
select distinct DATEFROMPARTS(year(dt), month(dt), day(dt)) as date
, name
, min(dt) over(partition by Datepart(dy, dt), name) as first
, max(dt) over(partition by Datepart(dy, dt), name) as last
, concat(year(dt), month(dt), day(dt), name) conc_col
from employees
where name <> 'noname'
order by name