I have three columns of time series data. I would like to plot the three time series one upon another beautifully in one plot. A star needs to be placed in the respective 5th, 8th, and 10th data points of each time series. My goal is to implement it in Python. I would appreciate if Experts could offer a more efficient method of doing it.
My code:
import matplotlib.pyplot as plt
import numpy as np
data=np.loadtxt("data_3_timeseries")
data.plot()
plt.show()
data_3_timeseries is attached here
-0.00831 -0.0213 -0.0182
0.0105 -0.00767 -0.012
0.00326 0.0148 -0.00471
-0.0263 -0.00318 0.011
0.012 0.0398 0.0117
-0.0156 -0.0133 0.02
-0.0482 -0.00783 -0.0162
0.0103 -0.00639 0.0103
0.0158 0.000788 -0.00484
-0.000704 -0.0236 0.00579
0.00151 -0.0135 -0.0195
-0.0163 -0.00185 0.00722
0.0207 0.00998 -0.0387
-0.0246 -0.0274 -0.0108
0.0123 -0.0155 0.0137
-0.00963 0.0023 0.0305
-0.0147 0.0255 -0.00806
0.000488 -0.0187 5.29e-05
-0.0167 0.0105 -0.0204
0.00653 0.0176 -0.00643
0.0154 -0.0136 0.00415
-0.0147 -0.00339 0.0175
-0.0238 -0.00284 0.0204
-0.00629 0.0205 -0.017
0.00449 -0.0135 -0.0127
0.00843 -0.0167 0.00903
-0.00331 7.2e-05 -0.00281
-0.0043 0.0047 0.00681
-0.0356 0.0214 0.0158
-0.0104 -0.0165 0.0092
0.00599 -0.0128 -0.0202
0.015 -0.0272 0.0117
0.012 0.0258 -0.0154
-0.00509 -0.0194 0.00219
-0.00154 -0.00778 -0.00483
-0.00152 -0.0451 0.0187
0.0271 0.0186 -0.0133
-0.0146 -0.0416 0.0154
-0.024 0.00295 0.006
-0.00889 -0.00501 -0.028
-0.00555 0.0124 -0.00406
-0.0185 -0.0114 0.0224
0.0143 0.0204 -0.0193
-0.0168 -0.00608 0.00178
-0.0159 0.0189 0.0109
-0.0213 -0.007 -0.0323
0.0031 0.0207 -0.00333
-0.0202 -0.0157 -0.0105
0.0159 0.00216 -0.0262
0.0105 -0.00292 0.00447
0.0126 0.0163 -0.0141
0.01 0.00679 0.025
0.0237 -0.0142 -0.0149
0.00394 -0.0379 0.00905
-0.00803 0.0186 -0.0176
-0.013 0.0162 0.0208
-0.00197 0.0313 -0.00804
0.0218 -0.0249 0.000412
-0.0164 0.00681 -0.0109
-0.0162 -0.00795 -0.00279
-0.01 -0.00977 -0.0194
-0.00723 -0.0464 0.00453
-0.000533 0.02 -0.0193
0.00706 0.0391 0.0194
CodePudding user response:
Something like this? Note: I did not use your columns correctly, but the principle stands.
markers = [5, 8, 10]
plt.plot(data[:len(data) // 3],
color='Blue',)
for marker in markers:
plt.plot(marker,
data[:len(data) // 3][marker],
marker="*",
color='blue')
plt.plot(data[len(data) // 3 : len(data) // 3 * 2],
color='orange')
plt.plot(data[len(data) // 3 * 2 : len(data) // 3 * 3],
color='green')
I only placed markers for the first data column, but you can do the same for all the columns.
Output:
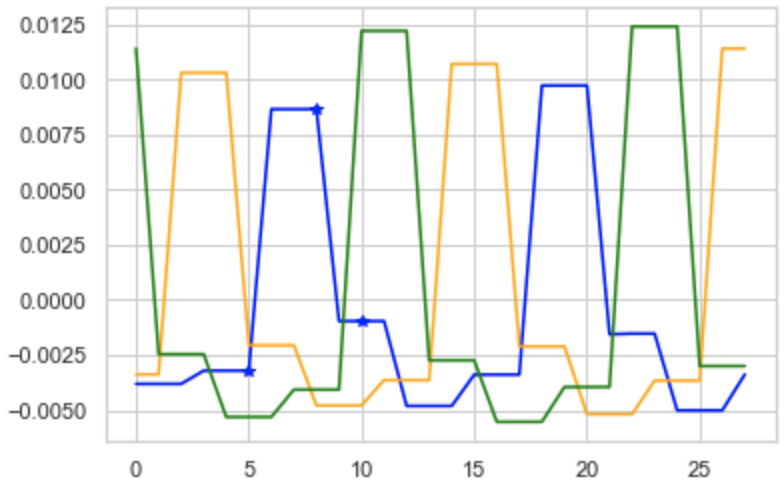
You can of course further prettify your plot. Enough options with Matplot.
CodePudding user response:
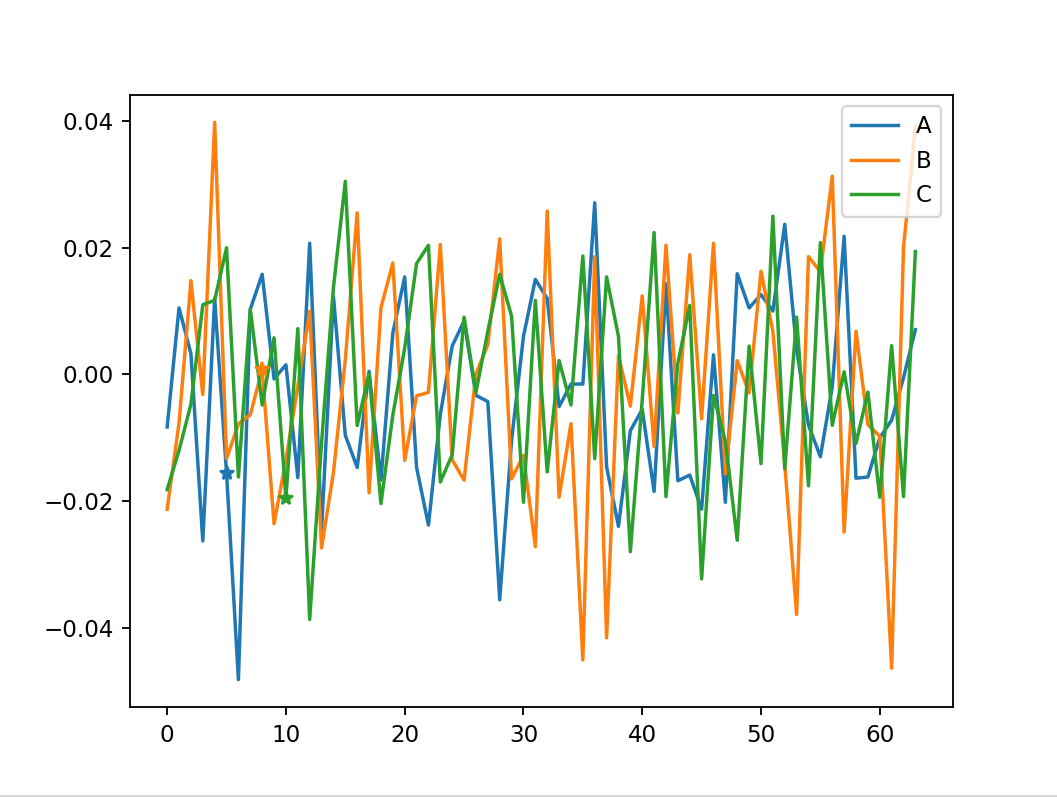
Due to your identical columns, the lines are lining one over the other.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
data = pd.DataFrame(np.loadtxt("data_3_timeseries"), columns=list('ABC'))
ax = data.plot()
for col, place, line in zip(list('ABC'), [5, 8, 10], ax.lines):
ax.plot(place, data[col][place], marker="*", c=line.get_color())
plt.show()
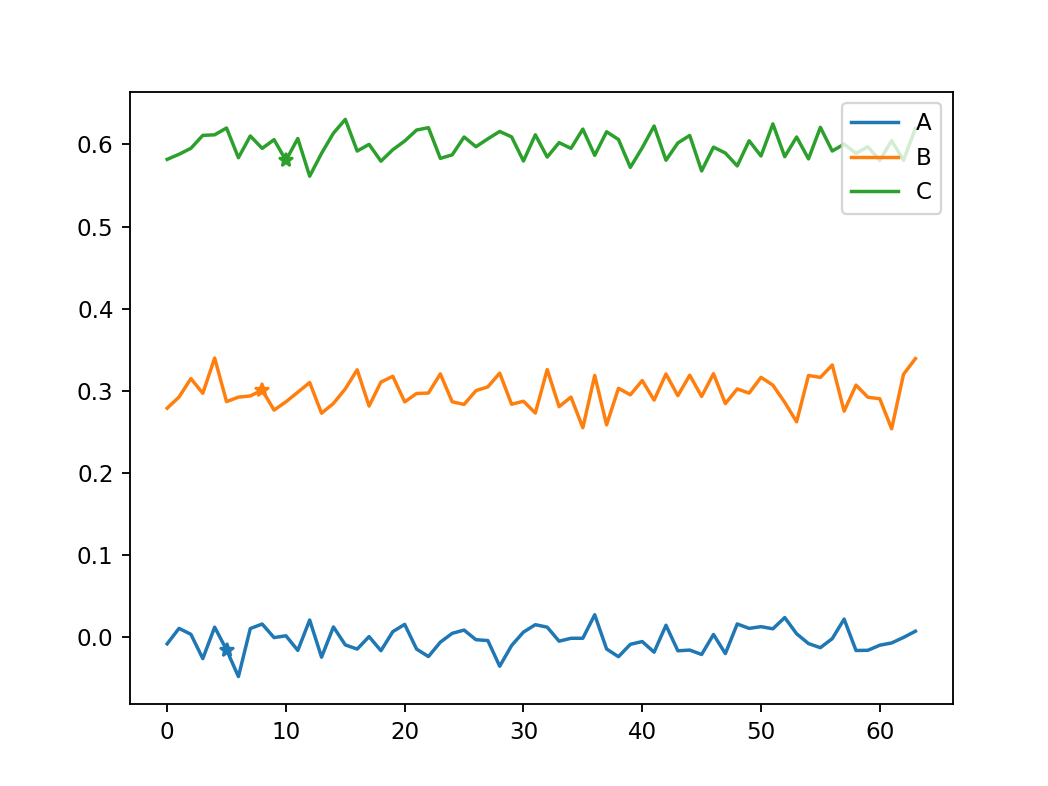
"NORMALIZED"
data = pd.DataFrame(np.loadtxt("data_3_timeseries"), columns=list('ABC'))
data['B'] = data['B'].apply(lambda x: x 0.3)
data['C'] = data['C'].apply(lambda x: x 0.6)
ax = data.plot()
for col, place, line in zip(list('ABC'), [5, 8, 10], ax.lines):
ax.plot(place, data[col][place], marker="*", c=line.get_color())
plt.show()