I am trying to find when the overlap start and when it ended in following DF.
I am able to determine the overlap cluster using below code, and now I want to find out when the overlap begins and when it ends
d = [
{'G1': 'A', 'G2': 'A1','Start_Date': '6/1/2020', 'End_Date': '5/31/2022'},
{'G1': 'B', 'G2': 'A1','Start_Date': '12/1/2020', 'End_Date': '11/30/2021'},
{'G1': 'B', 'G2': 'B1','Start_Date': '6/1/2020', 'End_Date': '5/31/2021'},
{'G1': 'Y', 'G2': 'B1','Start_Date': '6/1/2021', 'End_Date': '6/1/2022'},
{'G1': 'C', 'G2': 'C1','Start_Date': '1/1/2020', 'End_Date': '3/31/2020'},
{'G1': 'C', 'G2': 'C1','Start_Date': '4/1/2020', 'End_Date': '5/31/2020'},
{'G1': 'C', 'G2': 'C2','Start_Date': '6/1/2020', 'End_Date': '7/31/2020'},
{'G1': 'I', 'G2': 'C3','Start_Date': '8/1/2020', 'End_Date': '10/31/2020'},
{'G1': 'O', 'G2': 'C3','Start_Date': '11/1/2020', 'End_Date': '12/31/2021'},
{'G1': 'D', 'G2': 'D1','Start_Date': '1/1/2020', 'End_Date': '2/28/2020'},
{'G1': 'R', 'G2': 'D2','Start_Date': '3/1/2020', 'End_Date': '3/31/2020'},
{'G1': 'F', 'G2': 'D4','Start_Date': '4/1/2020', 'End_Date': '8/31/2020'},
{'G1': 'Y', 'G2': 'D4','Start_Date': '8/1/2020', 'End_Date': '10/31/2020'},
{'G1': 'D', 'G2': 'D4','Start_Date': '11/1/2020', 'End_Date': '12/31/2021'},
]
df = pd.DataFrame(d)
df['Start_Date'] = pd.to_datetime(df['Start_Date'],format='%m/%d/%Y', errors='coerce')
df['End_Date'] = pd.to_datetime(df['End_Date'],format='%m/%d/%Y', errors='coerce')
df['Range'] = df.apply(lambda x: pd.date_range(start=x['Start_Date'], end=x['End_Date']), axis=1)
def determine_cluster(group):
bucket = pd.DatetimeIndex(['1/1/1900'])
for x in group:
if x.isin(bucket).any():
return [True]*len(group)
bucket = bucket.append(x)
return [False]*len(group)
df['Cluster'] = df.groupby(['G2'])['Range'].transform(determine_cluster)
df.drop('Range', axis=1)
It Give below result:
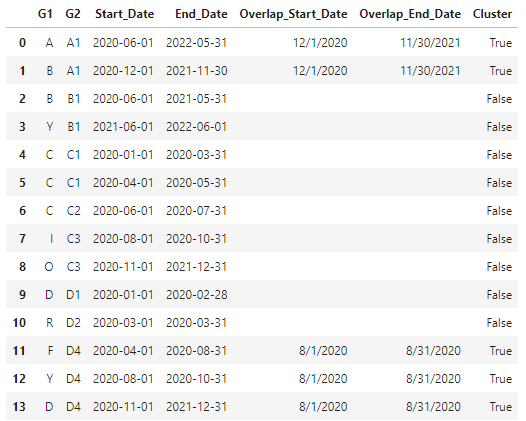
However my Desired output is:
Columns having groupby(cluster) overlap start and end date
CodePudding user response:
Try:
def fn(x):
z = (
x.apply(
lambda y: pd.date_range(y["Start_Date"], y["End_Date"]),
axis=1,
)
.explode()
.sort_values()
)
y = z[z.duplicated()]
y = y[(y.diff() != pd.Timedelta("1d")).cumsum() == 1]
if len(y) == 0:
x["Cluster"] = False
else:
x["Overlap_Start_Date"] = y.iloc[0]
x["Overlap_End_Date"] = y.iloc[-1]
x["Cluster"] = True
return x
x = df.groupby("G2").apply(fn)
print(x)
Prints:
G1 G2 Start_Date End_Date Overlap_Start_Date Overlap_End_Date Cluster
0 A A1 2020-06-01 2022-05-31 2020-12-01 2021-11-30 True
1 B A1 2020-12-01 2021-11-30 2020-12-01 2021-11-30 True
2 B B1 2020-06-01 2021-05-31 NaT NaT False
3 Y B1 2021-06-01 2022-06-01 NaT NaT False
4 C C1 2020-01-01 2020-03-31 NaT NaT False
5 C C1 2020-04-01 2020-05-31 NaT NaT False
6 C C2 2020-06-01 2020-07-31 NaT NaT False
7 I C3 2020-08-01 2020-10-31 NaT NaT False
8 O C3 2020-11-01 2021-12-31 NaT NaT False
9 D D1 2020-01-01 2020-02-28 NaT NaT False
10 R D2 2020-03-01 2020-03-31 NaT NaT False
11 F D4 2020-04-01 2020-08-31 2020-08-01 2020-08-31 True
12 Y D4 2020-08-01 2020-10-31 2020-08-01 2020-08-31 True
13 D D4 2020-11-01 2021-12-31 2020-08-01 2020-08-31 True
CodePudding user response:
You can use:
# Remove after this line:
df['Range'] = df.apply(lambda x: pd.date_range(start=x['Start_Date'],
end=x['End_Date']), axis=1)
# Replace by:
def determine_cluster_and_overlap(sr):
x = pd.Series(np.hstack(sr)).value_counts(sort=False).loc[lambda x: x > 1]
cluster = any(x > 1)
start = x.index[0].strftime('%-m/%-d/%Y') if cluster else pd.NaT
end = x.index[-1].strftime('%-m/%-d/%Y') if cluster else pd.NaT
return pd.Series({'Cluster': cluster,
'Overlap_Start_Date': start,
'Overlap_End_Date': end})
df = df.merge(df.pop('Range').groupby(df['G2'])
.apply(determine_cluster_and_overlap)
.unstack(level=1), on='G2')
Output:
>>> df
G1 G2 Start_Date End_Date Cluster Overlap_Start_Date Overlap_End_Date
0 A A1 2020-06-01 2022-05-31 True 12/1/2020 11/30/2021
1 B A1 2020-12-01 2021-11-30 True 12/1/2020 11/30/2021
2 B B1 2020-06-01 2021-05-31 False NaT NaT
3 Y B1 2021-06-01 2022-06-01 False NaT NaT
4 C C1 2020-01-01 2020-03-31 False NaT NaT
5 C C1 2020-04-01 2020-05-31 False NaT NaT
6 C C2 2020-06-01 2020-07-31 False NaT NaT
7 I C3 2020-08-01 2020-10-31 False NaT NaT
8 O C3 2020-11-01 2021-12-31 False NaT NaT
9 D D1 2020-01-01 2020-02-28 False NaT NaT
10 R D2 2020-03-01 2020-03-31 False NaT NaT
11 F D4 2020-04-01 2020-08-31 True 8/1/2020 8/31/2020
12 Y D4 2020-08-01 2020-10-31 True 8/1/2020 8/31/2020
13 D D4 2020-11-01 2021-12-31 True 8/1/2020 8/31/2020