When calling bound method this->UpdateB = std::bind(&Test::Update, this); (called using test.UpdateB()) its overall performance is considerably slower than calling the function directly. test.Update()
The performance decrease seams to also effect the work done in the method.
Using the site 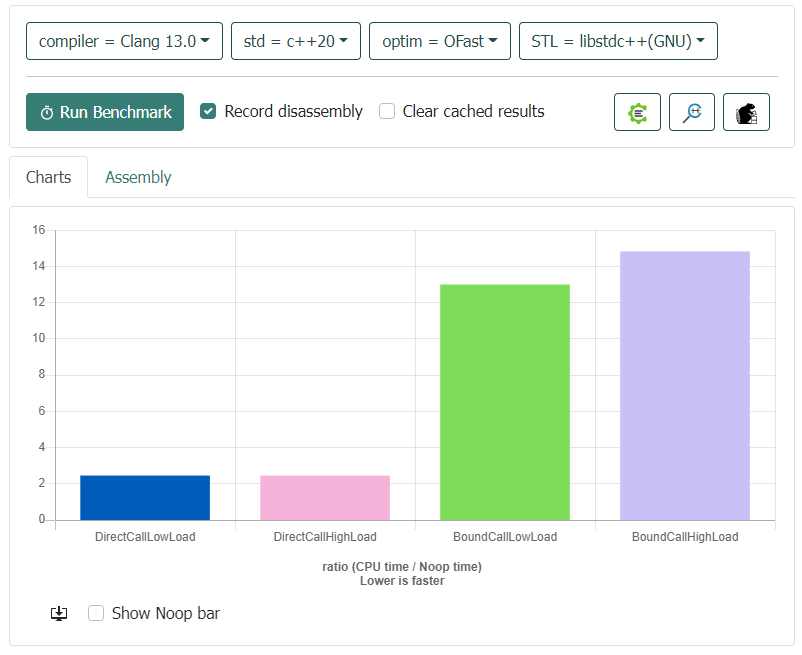
#include <functional>
#include <benchmark/benchmark.h>
typedef unsigned u32;
typedef uint64_t u64;
constexpr auto nP = nullptr;
constexpr bool _F = false;
constexpr bool _T = true;
constexpr u64 HIGH_LOAD = 1000000000;
constexpr u64 LOW_LOAD = 10;
struct Test {
u32 counter{100000};
u64 soak{0};
u64 load{10};
bool isAlive{_T};
std::function<bool()> UpdateB;
Test() { UpdateB = std::bind( &Test::Update, this); }
bool Update() {
if (counter > 0) { counter --; }
u64 i = load;
while(i--) { soak = 1; }
isAlive = counter > 0;
return isAlive;
}
};
static void DirectCallLowLoad(benchmark::State& state) {
Test test;
test.load = LOW_LOAD;
for (auto _ : state) { test.Update(); }
}
BENCHMARK(DirectCallLowLoad);
static void DirectCallHighLoad(benchmark::State& state) {
Test test;
test.load = HIGH_LOAD;
for (auto _ : state) { test.Update(); }
}
BENCHMARK(DirectCallHighLoad);
static void BoundCallLowLoad(benchmark::State& state) {
Test test;
test.load = LOW_LOAD;
for (auto _ : state) { test.UpdateB(); }
}
BENCHMARK(BoundCallLowLoad);
static void BoundCallHighLoad(benchmark::State& state) {
Test test;
test.load = HIGH_LOAD;
for (auto _ : state) { test.UpdateB(); }
}
BENCHMARK(BoundCallHighLoad);
The expectation is that...
BoundCallHighLoadperformance would get closer toDirectCallHighLoadas the call overhead has less effect compared to the method's load .DirectCallLowLoadperformance would be significantly better thanDirectCallHighLoad(same for bound calls.)Bound calls would not be almost 5 times slower than direct calls.
What is wrong with my code?
Why are bound calls so slow?
If I use
std::function<bool(Test*)> UpdateB;
Test() { UpdateB = &Test::Update; } // Test constructor
// call using
test.UpdateB(&test);
it gets even worse, the call test.UpdateB(&test); is many magnitudes slower than the direct call test.Update() with processing load making little to no difference.
CodePudding user response:
First of all, there is a "Show Noop bar" to see the overhead of a noop instruction (theoretically 1 cycle). Here is the result:
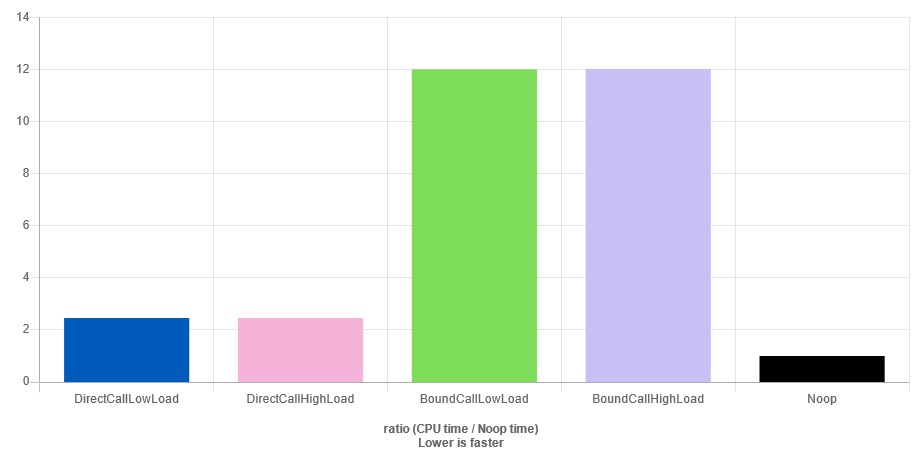
Thus, one can clearly see that DirectCallLowLoad and DirectCallHightLoad are optimized out and the benchmark is biased. Indeed, this is impossible for a CPU to execute 1000000000 iterations in about 2 cycles. In fact, it is not even possible to do 10 iterations. The same thing applies for the two other though there is an additional overhead.
The reason why this code is optimized is that Clang is able to know that repeating soak = 1; load times is equivalent to adding load to soak. In fact, it can does more advanced mathematical operations like 1 2 3 ... N = N*(N-1)/2. It is not easy to trick a compiler but one solution is to computes things that are mathematically proven to be hard like computing the hailstone sequence for example. If a compiler is able to optimize this, then it would be able to prove the Collatz conjecture which is not yet proven. Note it is better if the compiler cannot know the initial value which should be the purpose of the QuickBench loop state. Note also that any random number general could potentially also do the job.
UpdateB is slower than Update because of the additional runtime indirection. While compilers could theoretically optimize such a code thanks to specialization, they often do not in by default because it would be too expensive. In fact, in this specific benchmark, they can hardly do that without any help since the QuickBench loop state should prevent compiler to optimize it. One solution to reduce this overhead is to use profile-guided optimizations so the compiler can make speculative optimizations based on the actual function set in practice. That being said, it should still not be enough in this QuickBench due to to the loop state.
Note that you can see the assembly code in QuickBench directly and see for example that the code is inlined for the first two cases. Here is the main loop of the first bench:
mov