How to extract text from PDF files for below PDF format. PyPDF2 does not extract the text in a proper readable format.
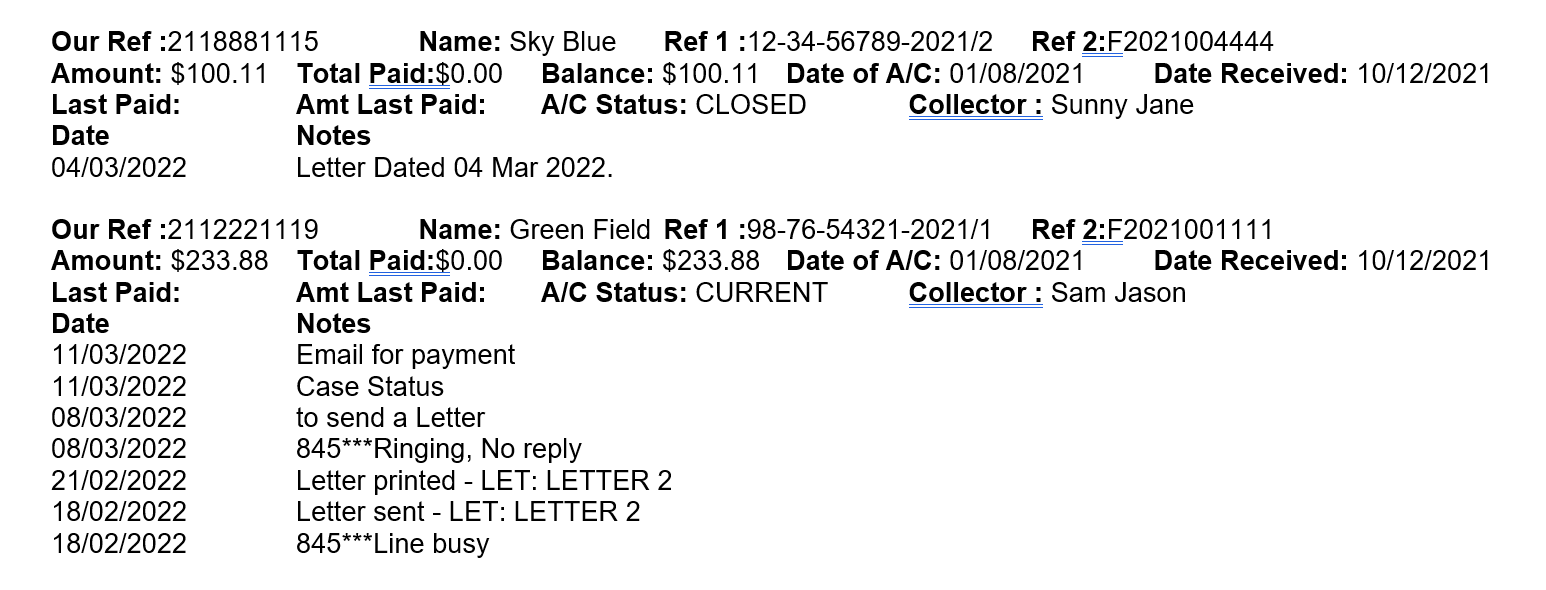
I have explored PyPDF2 and Pandas. Both are able to extract the data but data is stored as 1 column. I need to store the extracted data as csv files in this desired format.

This is what I have tried
import PyPDF2
import openpyxl
from openpyxl import Workbook
pdfFileObj = open('sample.pdf', 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
pdfReader.numPages
pageObj = pdfReader.getPage(0)
mytext = pageObj.extractText()
wb = Workbook()
sheet = wb.active
sheet.title = 'MyPDF'
sheet['A1'] = mytext
wb.save('sample.xlsx')
print('Save')
You can download the pdf file from this link
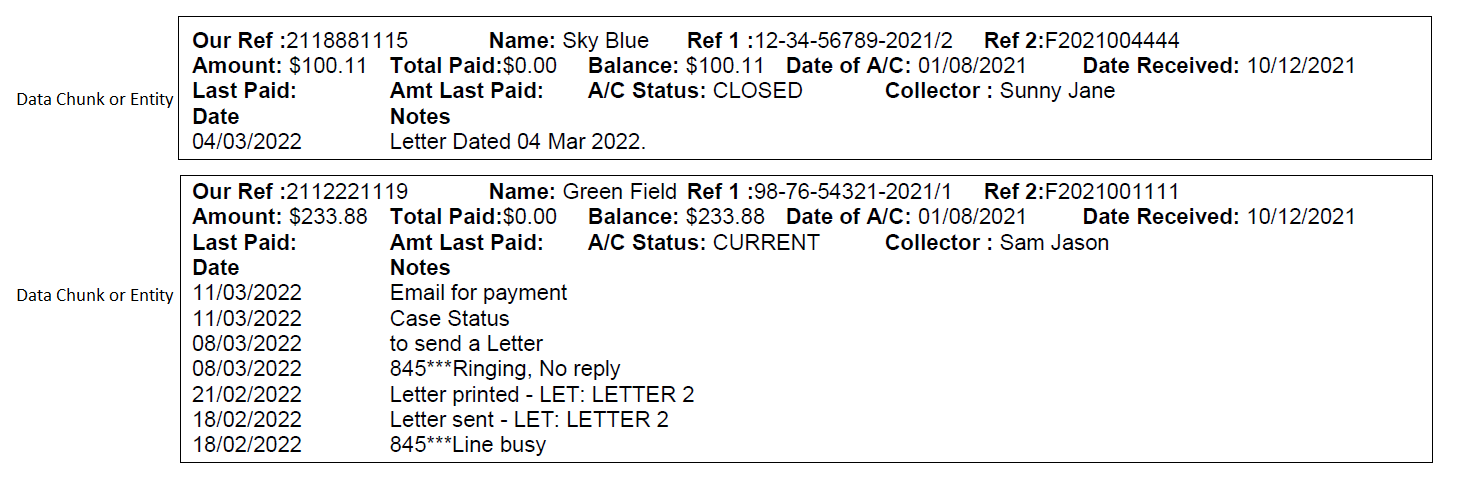
Line 1
Our Ref:
Name:
Ref 1:
Ref 2:
Line2
Amount:
Total Paid:
Balance:
Date of A/C:
Date Received:
Line3
Last Paid:
Amt Last Paid:
A/C Status:
Collector :
Line4
Date (Column name)
Notes (Column name)
And then multiple line of Date and Notes values
- I assume that each data will be separated by one new blank line. As shown here.

Also there will be no other attributes apart from the ones listed above in your data.
Also there will always be 3 line of actual key:value and then the table for Date and Notes start.
CODE
Before you move ahead please install the package pdfplumber
pip install pdfplumber
All you need to change in the below code is the pdf_path
import pdfplumber
import re
# regex pattern for keys in line1
my_regex_dict_line1 = {
'Our Ref' : r'Our Ref :(.*?)Name',
'Name' : r'Name:(.*?)Ref 1',
'Ref 1' : r'Ref 1 :(.*?)Ref 2',
'Ref 2' : r'Ref 2:(.*?)$'
}
# regex pattern for keys in line2
my_regex_dict_line2 = {
'Amount' : r'Amount:(.*?)Total Paid',
'Total Paid' : r'Total Paid:(.*?)Balance',
'Balance' : r'Balance:(.*?)Date of A/C',
'Date of A/C' : r'Date of A/C:(.*?)Date Received',
'Date Received' : r'Date Received:(.*?)$'
}
# regex pattern for keys in line3
my_regex_dict_line3 ={
'Last Paid' : r'Last Paid:(.*?)Amt Last Paid',
'Amt Last Paid' : r'Amt Last Paid:(.*?)A/C Status',
'A/C Status': r'A/C Status:(.*?)Collector',
'Collector' : r'Collector :(.*?)$'
}
def split_on_empty_lines(s):
''' This function splits the pdf on data chunks and returns the data chunk in list '''
blank_line_regex = r"\n *\n{1}"
return re.split(blank_line_regex, s.strip())
def iterate_through_regex_and_populate_dictionaries(data_dict, regex_dict, text):
''' For the given pattern of regex_dict, this function iterates through each regex pattern and adds the key value to regex_dict dictionary '''
for key, regex in regex_dict.items():
matched_value = re.search(regex, text)
if matched_value is not None:
data_dict[key] = matched_value.group(1).strip()
def populate_date_notes(data_dict, text):
''' This function populates date and Notes in the data chunk in the form of list to data_dict dictionary '''
data_dict['Date'] = []
data_dict['Notes'] = []
iter = 4
while(iter < len(text)):
date_match = re.search(r'(\d{2}/\d{2}/\d{4})',text[iter])
data_dict['Date'].append(date_match.group(1).strip())
notes_match = re.search(r'\d{2}/\d{2}/\d{4}\s*(.*?)$',text[iter])
data_dict['Notes'].append(notes_match.group(1).strip())
iter = 1
if(__name__ == '__main__'):
pdf_path = r'C:\Users\hpoddar\Desktop\Temp\sample.pdf' # ENTER YOUR PDF PATH HERE
pdf_text = None
json_data = []
with pdfplumber.open(pdf_path) as pdf:
first_page = pdf.pages[0]
pdf_text = first_page.extract_text()
data_list = split_on_empty_lines(pdf_text)
for data in data_list:
# split by new line in data chunks
data_after_split_on_new_line = re.split(r"\n", data.strip())
data_dict = {}
# Process line 1 in the data chunk
iterate_through_regex_and_populate_dictionaries(data_dict, my_regex_dict_line1, data_after_split_on_new_line[0])
# Process line 2 in the data chunk
iterate_through_regex_and_populate_dictionaries(data_dict, my_regex_dict_line2, data_after_split_on_new_line[1])
# Process line 3 in the data chunk
iterate_through_regex_and_populate_dictionaries(data_dict, my_regex_dict_line3, data_after_split_on_new_line[2])
# Check if the next line conatins table column Date and Notes
if(len(data_after_split_on_new_line) > 3 and data_after_split_on_new_line[3] != None and 'Date' in data_after_split_on_new_line[3] and 'Notes' in data_after_split_on_new_line[3]):
populate_date_notes(data_dict, data_after_split_on_new_line)
json_data.append(data_dict)
print(json_data)
This gives us the data in a clean elegant way in json format.

Now that we got the data in a json format, we can load it in a csv, text or data frame format.
Please let me know if you need any information on any part of the code or you need the full explanation of the code.
CodePudding user response:
Firstly install tabula by the following command pip install tabula-py
# Import the required Module
import tabula
# Read a PDF File
df = tabula.read_pdf("sample.pdf", pages='all')[0]
# convert PDF into CSV
tabula.convert_into("sample.pdf", "sample.csv", output_format="csv", pages='all')
print(df)
CodePudding user response:
I was going to suggest that many extractors work using poppler as their pdf to text engine so to split into columns you could expect something like
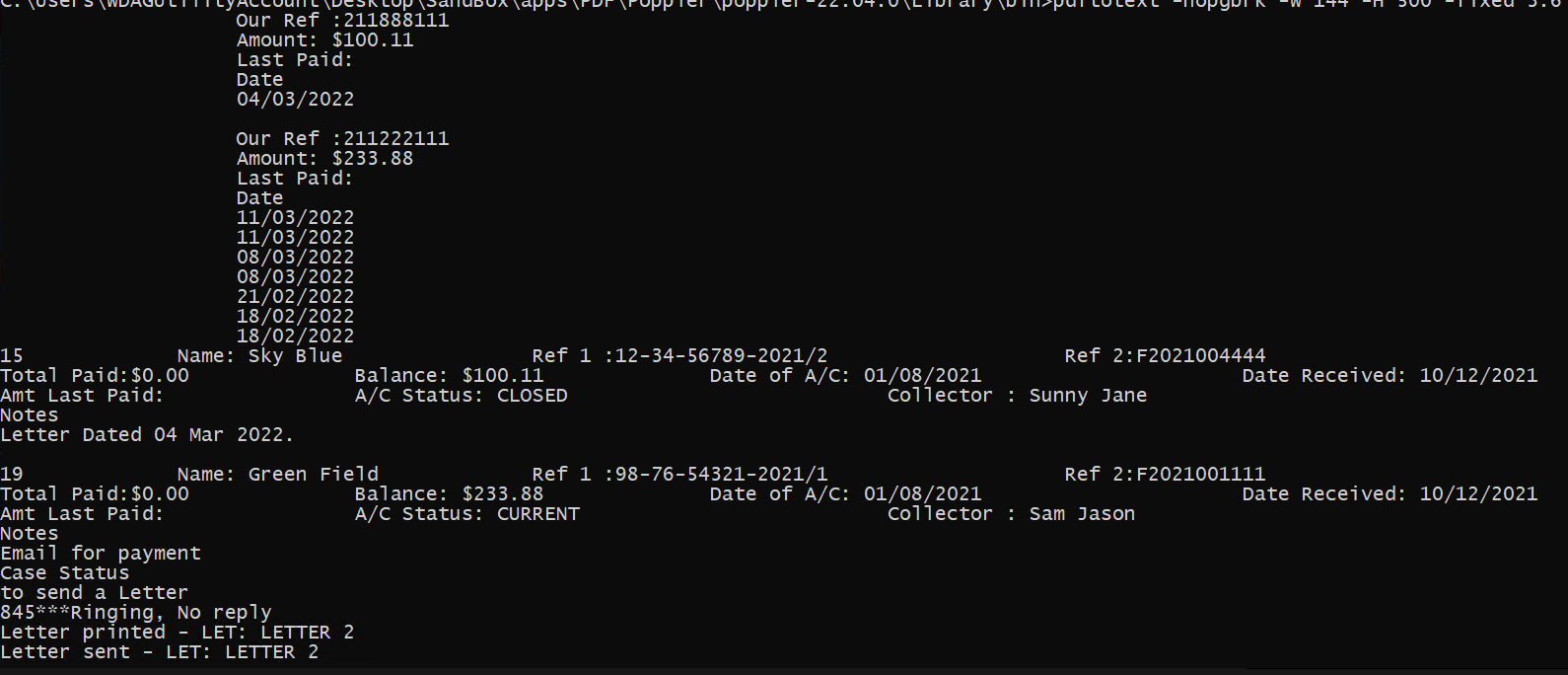
However there simply is too much overlap in the various staggered rows. That such an approach would be very variable. However as suggested, the simpler method is work with the bold text features. Thus I would be using a Find and Replace method to add commas to the single column that the page layout provides.
You need , after every /2022, or similar /2021,
likewise before every ,Name: ,Ref # : ,Total Paid: etc
The simplest way is export pdftotext -layout (with any other preferences) out.txt, then parse the text to inject the commas but watch out for existing so 845***Ringing, No reply can be left as it is for 2 columns, but other cases may not be suited and need "quoting".
Your desired output does not match a csv input thus you need a much more custom clip of text after each row entry, then deal with the vertical first two columns as a separate 2nd step.