Here is a simple example
from pyspark.sql.functions import map_values
df = spark.sql("SELECT map('a', 1, 'c', 2, 'b', 3) as data")
df.show(20, False)
df.select(map_values("data").alias("values")).show()

What I want is the following (in the order of the keys: 'a', 'b', 'c')
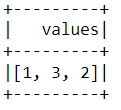
How to achieve this? In addition - does the result from map_values function always maintain the order in the df.show() above, i.e., [1, 2, 3]?
CodePudding user response:
The map's contract is that it delivers value for a certain key, and the entries ordering is not preserved. Keeping the order is provided by arrays.
What you can do is turn your map into an array with map_entries function, then sort the entries using array_sort and then use transform to get the values. A little convoluted, but works.
with data as (SELECT map('a', 1, 'c', 2, 'b', 3) as m)
select
transform(
array_sort(
map_entries(m),
(left, right) -> case when left.key < right.key then -1 when left.key > right.key then 1 else 0 end
),
e -> e.value
)
from data;
CodePudding user response:
An option using map_keys
from pyspark.sql import functions as F
df = spark.sql("SELECT map('a', 1, 'c', 2, 'b', 3) as data")
df = df.select(
F.transform(F.array_sort(F.map_keys("data")), lambda x: F.col("data")[x]).alias("values")
)
df.show()
# ---------
# | values|
# ---------
# |[1, 3, 2]|
# ---------