I have a data frame with multiple id in column id. For each day, I have 5 time steps. (6:00, 6:15, 6:30, 6:45, 7:00) However, some days does not have 5. And I want to fill the missing value as Nan.. Let see the following example,
import pandas as pd
df = pd.DataFrame()
df['id'] = [1, 1, 1, 1, 1, 2, 2, 2,3, 3]
df['val'] = [11, 10, 12, 3, 4, 5, 125, 45,31, -2]
df['date'] = ['2019-03-31 06:00:00','2019-03-31 06:15:00', '2019-03-31 06:30:00', '2019-03-31 06:45:00', '2019-03-31 07:00:00', '2019-03-31 06:00:00', '2019-03-31 06:30:00',
'2019-03-31 06:45:00', '2019-03-31 06:00:00', '2019-03-31 06:15:00']
df
For example, for id=1 we have 5 time steps.
For id=2, we have 3 time steps.
for id=3, we have 2 time steps.
So,
I want to sticks values in one rows and add only the day of the time to that row.
Here is the desired output for my data frame:
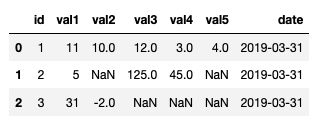
Can you help me with this? Thank you so much.
CodePudding user response:
One way using pandas.DataFrame.pivot:
df["dates"] = pd.to_datetime(df["date"]).dt.date
new_df = df.pivot(index=["id", "dates"], columns="date", values="val")
new_df.columns = [f"val{i 1}" for i in range(new_df.shape[1])]
new_df.reset_index()
Output:
id dates val1 val2 val3 val4 val5
0 1 2019-03-31 11.0 10.0 12.0 3.0 4.0
1 2 2019-03-31 5.0 NaN 125.0 45.0 NaN
2 3 2019-03-31 31.0 -2.0 NaN NaN NaN