I am trying to create a new DataFrame by selecting rows from an existing Df.
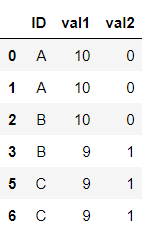
df:
ID val1 val2 uniq
A 10 0 1-2
A 10 0 3-2
B 10 0 8-0
B 9 1 7-6
B 8 2 9-3
c 9 1 10-3
c 9 1 3-0
I only want 2 rows for each ID based on preferences on col val1 & val2:
1) val1 == 10 & val2 == 0 (first preference)
2) val1 == 9 & val2 == 1 (second preference)
3) val1 == 8 & val2 == 2 (third preference)
Required output:
ID val1 val2 uniq
A 10 0 1-2
A 10 0 3-2
B 10 0 8-0
B 9 1 7-6
c 9 1 10-3
c 9 1 3-0
Is there any efficient way to do this in pandas? Thanks for your time!
CodePudding user response:
df.sort_values(['val1', 'val2'], ascending=[False, True]).groupby('ID').head(2)
ID val1 val2 uniq
0 A 10 0 1-2
1 A 10 0 3-2
2 B 10 0 8-0
3 B 9 1 7-6
5 c 9 1 10-3
6 c 9 1 3-0
Edit:
In the case where there might be some other type of combinations yet only the three above are to be taken into consideration then do:
a = (df[['val1', 'val2']].astype(str)
.apply(' '.join, axis = 1).astype('category'))
order = ['10 0', '9 1', '8 2']
levels = np.r_[order, a.cat.remove_categories(order).cat.categories]
df['a'] = a.cat.reorder_categories(levels).cat.as_ordered()
df.sort_values('a').groupby('ID').head(2).drop(columns='a')
ID val1 val2 uniq
0 A 10 0 1-2
1 A 10 0 3-2
2 B 10 0 8-0
3 B 9 1 7-6
5 c 9 1 10-3
6 c 9 1 3-0
CodePudding user response:
Going by your preferences, i did this
df = {'ID':['A', 'A', 'B', 'B', 'B', 'C', 'C'],
'val1': [10,10,10,9,8,9,9],
'val2': [0,0,0,1,2,1,1]}
df = pd.DataFrame(df)
df1 = df[(df['val1'] == 10) & (df['val2'] == 0)][:2]
df2 = df[(df['val1'] == 9) & (df['val2'] == 1)][:2]
df3 = df[(df['val1'] == 8) & (df['val2'] == 2)][:2]
df4 = df1.append(df2)
df = df4.append(df3)
df.sort_values(['ID'])
output
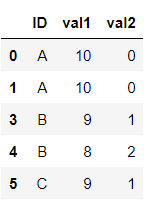
without preferences
df.groupby(['ID']).head(2)
output