I have a large dataframe with two columns and a datetime index. When plotting a section of it, it looks like this:
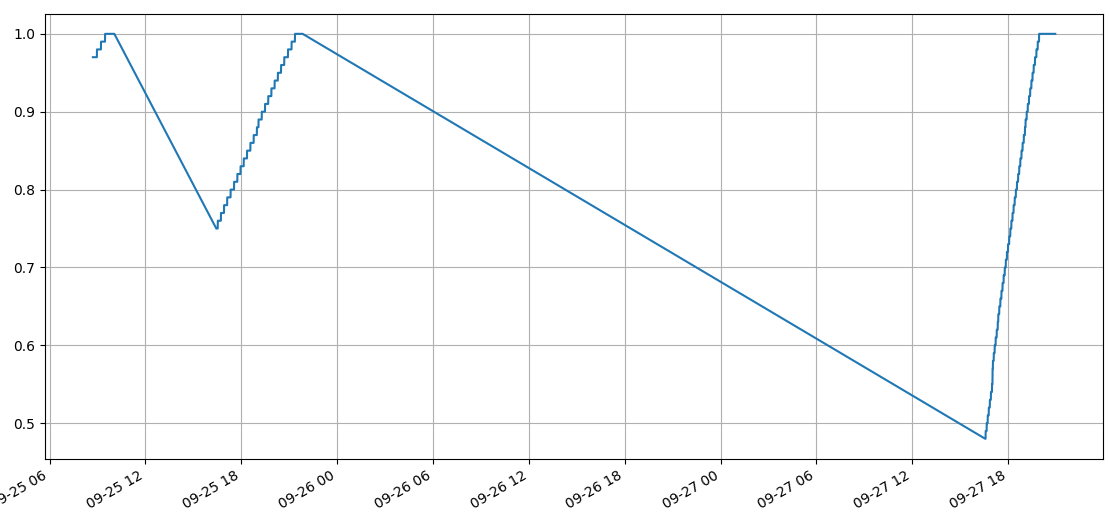
Basically, data can go up (charging) or down (discharging) (sometimes remaining constant through these cycles) according to the SOC column.
The dataframe looks like the following:
SoC Power
2021-09-25 16:40:00 0.76 2.18
2021-09-25 16:40:10 0.76 2.14
2021-09-25 16:40:20 0.77 2.18
2021-09-25 16:40:30 0.76 1.14
2021-09-25 16:40:30 0.75 1.14
2021-09-25 16:40:30 0.75 1.14
I want to extract the first charging and discharging cycles. In this example, the expected output would be new dataframes as:
"Charging":
SoC Power
2021-09-25 16:40:00 0.76 2.18
2021-09-25 16:40:10 0.76 2.14
2021-09-25 16:40:20 0.77 2.18
"Discharging"
SoC Power
2021-09-25 16:40:30 0.76 1.14
2021-09-25 16:40:30 0.75 1.14
2021-09-25 16:40:30 0.75 1.14
My closest approach for extracting a charging session was the following:
max = df_3['SoC'].diff() < 0
idx = max.idxmax()
df = df.loc[df.index[0]:idx]
However, it only works when the data starts with a charging session (as all it does is stop whenever the values begin to decrease). I want a solution that works despite the initial data point and gives me the first charging cycle data points.
I hope my explanation was clear, thanks in advance!
CodePudding user response:
I don't how the data is, but I think that creating a window walking through the data is a good idea and which pandas has a functionality for it.
I explain: The window starts small, it moves through the data and can potentially increase in size by checking if the pattern of increase or decrease is still there. In case of a change in pattern the window will be transformed to its original size and repeat the process until the end.
Hope it helps and good luck.
CodePudding user response:
The exact expected output is unclear, but here is an approach to split each phase (charging, discharging) in a dictionary (2 statuses: charging/discharging, with a list of all phases per status):
s = np.sign(df['SoC'].diff())
s2 = s.mask(s.eq(0)).ffill().bfill().map({1: 'charging', -1: 'discharging'})
from collections import defaultdict
out = defaultdict(list)
for (status,_), d in s2.groupby([s2, s2.ne(s2.shift()).cumsum()]):
out[status].append(d)
dict(out)
output:
{'charging': [2021-09-25 16:40:00 charging
2021-09-25 16:40:10 charging
2021-09-25 16:40:20 charging
Name: SoC, dtype: object],
'discharging': [2021-09-25 16:40:30 discharging
2021-09-25 16:40:30 discharging
2021-09-25 16:40:30 discharging
Name: SoC, dtype: object]}
For a single item:
out['charging'][0]
output:
2021-09-25 16:40:00 charging
2021-09-25 16:40:10 charging
2021-09-25 16:40:20 charging
Name: SoC, dtype: object
as DataFrame:
s = np.sign(df['SoC'].diff())
df['status'] = (s.mask(s.eq(0)).ffill().bfill()
.map({1: 'charging', -1: 'discharging'})
)
df['phase'] = s2.ne(s2.shift()).cumsum()
output:
SoC Power status phase
2021-09-25 16:40:00 0.76 2.18 charging 1
2021-09-25 16:40:10 0.76 2.14 charging 1
2021-09-25 16:40:20 0.77 2.18 charging 1
2021-09-25 16:40:30 0.76 1.14 discharging 2
2021-09-25 16:40:30 0.75 1.14 discharging 2
2021-09-25 16:40:30 0.75 1.14 discharging 2