My dataframe looks something like the following, where there are >100 columns that starts with "i10_" and many other columns with other data. I would like to create a new variable that tells me whether the values C7931 and C7932 are in each row within only the columns that start with "i10_". I would like to create a new variable that states TRUE or FALSE depending on whether the value exists in that row or not.
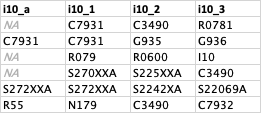
So the output would be c(TRUE, TRUE, FALSE, FALSE, FALSE, TRUE)
CodePudding user response:
Create a vector with the columns of interest and use rowSums(), i.e.
i1 <- grep('i10_', names(d1))
rowSums(d1[i1] == 'C7931' | d1[i1] == 'C7932', na.rm = TRUE) > 0
where,
d1 <- structure(list(v1 = c("A", "B", "C", "D", "E", "F"), i10_a = c(NA,
"C7931", NA, NA, "S272XXA", "R55"), i10_1 = c("C7931", "C7931",
"R079", "S272XXA", "S234sfs", "N179")), class = "data.frame", row.names = c(NA,
-6L))
CodePudding user response:
Ideally, you would give us a reproducible example with dput(). Assuming your dataframe is called df, you can do something like this with only base.
df$present <- apply(
df[, c(substr(names(df), 1, 3) == "i10")],
MARGIN = 1,
FUN = function(x){"C7931" %in% x & "C7932" %in% x})
This will go row by row and check columns that start with i10 if they contain "C7931" and "C7932".
CodePudding user response:
Similar approach with dplyr::across()
my_eval<-c("C7932","C7931")
d1%>%
mutate(is_it_here=
rowSums(across(starts_with("i10_"),
~. %in% my_eval))!=0)