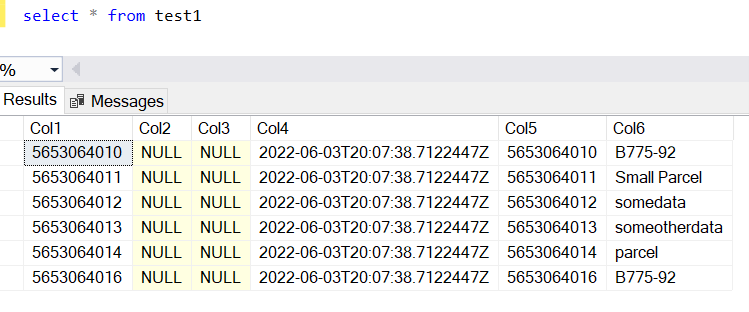
I am exporting F&O D365 data to ADLS in CSV format. Now, I am trying to read the CSV stored in ADLS and copy into Azure Synapse dedicated SQL pool table using Azure data factory. However, I can create the pipeline and it's working for few tables without any issue. But it's failing for one table (salesline) because of mismatch in number of column. Below is the CSV format sample, there is no column name(header) in CSV because it's exported from F&O system and column name stored in salesline.CDM.json file.
5653064010,,,"2022-06-03T20:07:38.7122447Z",5653064010,"B775-92"
5653064011,,,"2022-06-03T20:07:38.7122447Z",5653064011,"Small Parcel"
5653064012,,,"2022-06-03T20:07:38.7122447Z",5653064012,"somedata"
5653064013,,,"2022-06-03T20:07:38.7122447Z",5653064013,"someotherdata",,,,test1, test2
5653064014,,,"2022-06-03T20:07:38.7122447Z",5653064014,"parcel"
5653064016,,,"2022-06-03T20:07:38.7122447Z",5653064016,"B775-92",,,,,,test3
I have created ADF pipeline using copy data activity to copy the data from ADLS(CSV) to Synapse SQL table however I am getting below error.
Operation on target Copy_hs1 failed: ErrorCode=DelimitedTextMoreColumnsThanDefined,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Error found when processing 'Csv/Tsv Format Text' source 'SALESLINE_00001.csv' with row number 4: found more columns than expected column count 6.,Source=Microsoft.DataTransfer.Common,'
Column mapping looks like below- Because CSV first row has 6 column so it's appearing 6 only while importing schema.

CodePudding user response:
I have repro’d with your sample data and got the same error while copying the file using the copy data activity.
Alternatively, I have tried to copy the file using data flow and was able to load the data without any errors.
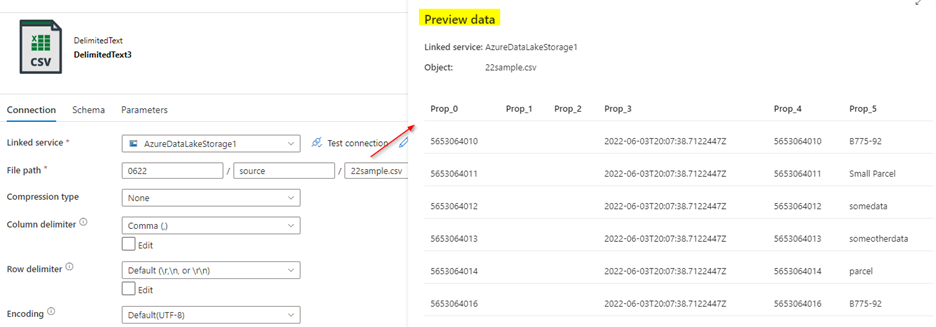
Source file:

Data flow:
Source dataset: only the first 6 columns are read as the first row contains only 6 columns in the file.
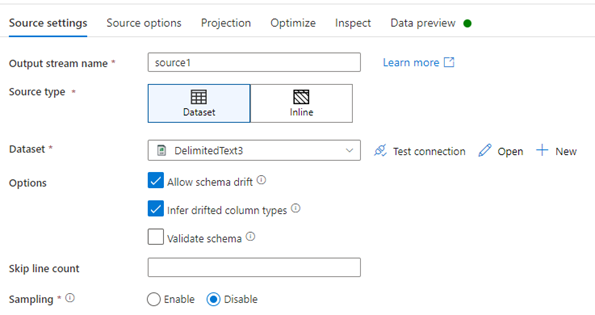
Source transformation: connect source dataset in source transformation.
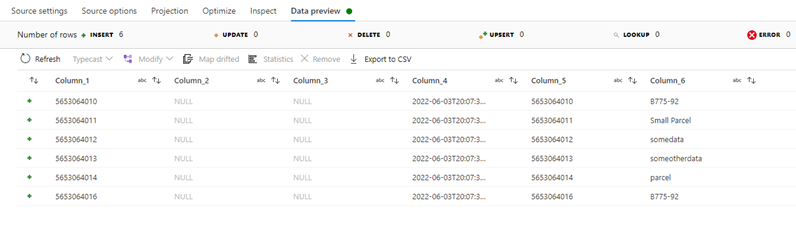
Source preview:
Sink transformation: Connect sink to synapse dataset.
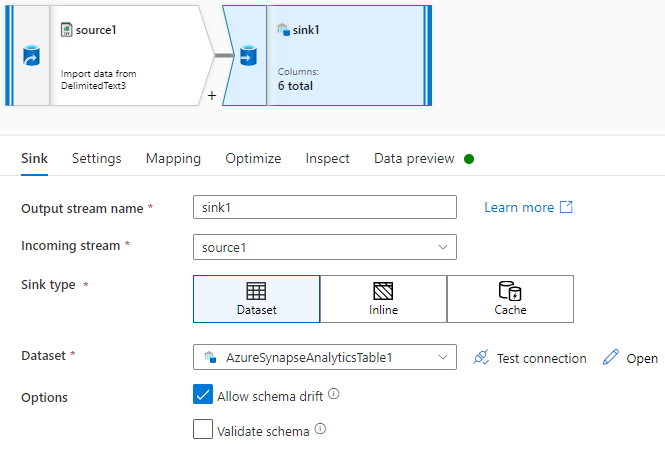
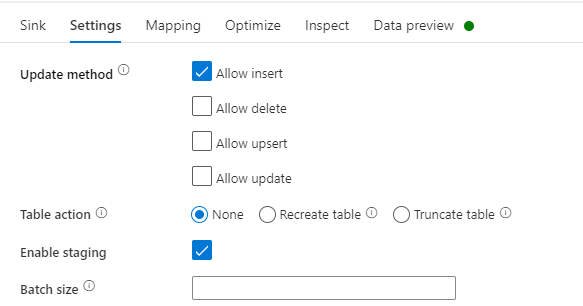
Settings:
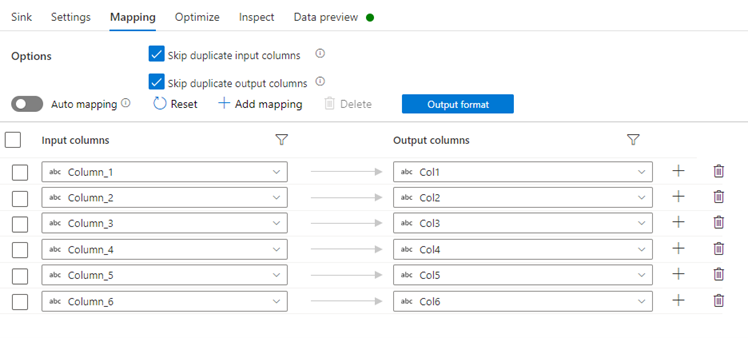
Mappings:
Sink output:
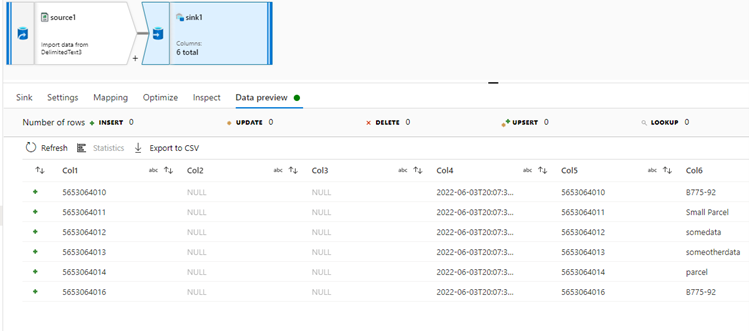
- After running the data flow, data is loaded to the sink synapse table.